Evidence-based clinical sciences are currently suffering from a paralyzing reproducibility crisis. From clinical psychiology to cancer biology, recent metaresearch indicates a rise in researchers failing to replicate studies published by their peers. This problem is not just limited to benchwork that happens in a lab; it also plagues translational research where the transformation from bench to bedside happens. Treatments, tests, and technologies are converted from simple lab experiments to government-approved devices and assays that affect hundreds of lives. Therefore, replicability is crucial to converting scientific breakthroughs into pragmatic remedies.
The primary role of blockchain technology in the emerging landscape of open-access science is increasing the amount of transparency into the processes. To that end, three use cases and applications are presented in this chapter: The first one involves deposition of data in clinical trials, the second one involves a reputation system that can be developed for researchers and institutes committed to open research, and the third one involves the application of supply-chain management for tracking counterfeit drugs.
We begin by discussing the current paradigms of the research method and the importance of negative data, and our focus remains limited primarily to the clinical sciences. Then, we talk about traditional metrics and altmetrics systems presently implemented to measure the impact of published research. This allows us to transition into the use cases that supplement traditional metrics and expand them to make open science a fundamental feature. Finally, we end our discussion by looking at ongoing efforts in psychology research to incorporate prediction markets to verify research, and how prediction markets can be created using Augur.
Reproducibility Crisis
Let’s begin our discussion with what reproducibility means in the context of scientific discourse and investigation. One of the major cornerstones in research is the ability to follow written protocols from a study, using the documented methods to carry out experiments and arrive at the same conclusions given by that study. In other words, a published study can be independently verified by other researchers, and replicated to give the same results. Recent metaresearch in clinical sciences demonstrates that more and more published works are not rigorous enough experimentally to be replicated with ease. Freedman et al. estimated that over 50 percent of preclinical research cannot be translated from animal models to human clinical trials, thereby placing the approximate annual cost of irreproducibility at $28 billion in the United States alone. Consequently, as preclinical findings in animal models are rarely repeated in clinical trials, drug discovery has slowed down and costs have risen dramatically. The economic costs are very debilitating; close to $200 billion is wasted annually because the discovered targets cannot be reproduced.
These problems are often inherent to the design of a particular study, or due to very genuine intricacies and complications that arise in experiments on differing cell lines. To understand why, we have to look for answers in metaresearch, which is a branch of investigation that statistically evaluates the claims, results, and experiments performed in a study.
© Vikram Dhillon, David Metcalf, and Max Hooper 2017
111
V. Dhillon et al., Blockchain Enabled Applications, https://doi.org/10.1007/978-1-4842-3081-7_8
Chapter 8 ■ BloCkChain in SCienCe
A multitude of factors in academia are creating a vicious culture of “bad science,” as Dr. Ben Goldacre referred to it: a vanishing funding environment, a culture of “publish or perish,” and an incredible amount of pressure to get tenured pushes young researchers to follow erroneous methods to get published. In some cases, the slipshod research methods and manipulations have led to fraud and eventual retractions with serious consequences to the researcher.
■ Note retraction Watch (http://retractionwatch.com/) is a blog that recently came about to report on scientific misconduct happening at all levels, from editors working with journals to individual researchers at universities. the blog also tracks papers that have been retracted from journals due to fraudulent data or manipulation of experimental evidence. the interested reader can follow their web site, which posts about 500
to 600 retractions per year.
Academic journals are also partially to blame for this mess, although there are signs of real change and improvement in the works. Over the past years, it has been easier to publish studies with positive findings in journals regarding potential drug targets or effectiveness of a particular drug. Negative findings from experiments, such as a drug target not working even though it was expected to work, have been incredibly difficult to publish, however. At face value, it seems to make sense: Why would someone want to know if an experiment failed? Negative data usually get ignored because of similar reasoning, and from a marketing standpoint, a journal claiming that something did not work as expected is not a highlight that would sell.
Let’s take a closer look at positive and negative data in the context of how journals have shaped their use and publication.
Positive data simply confirm an initial hypothesis, where a researcher predicted a finding and the data validate it. On the other hand, negative data come from the cases where the expected or desired effect was not observed. If an experiment showed that no difference exists between the null and alternative hypotheses, the data and results will likely end up buried in the pile of unpublished results of the lab group.
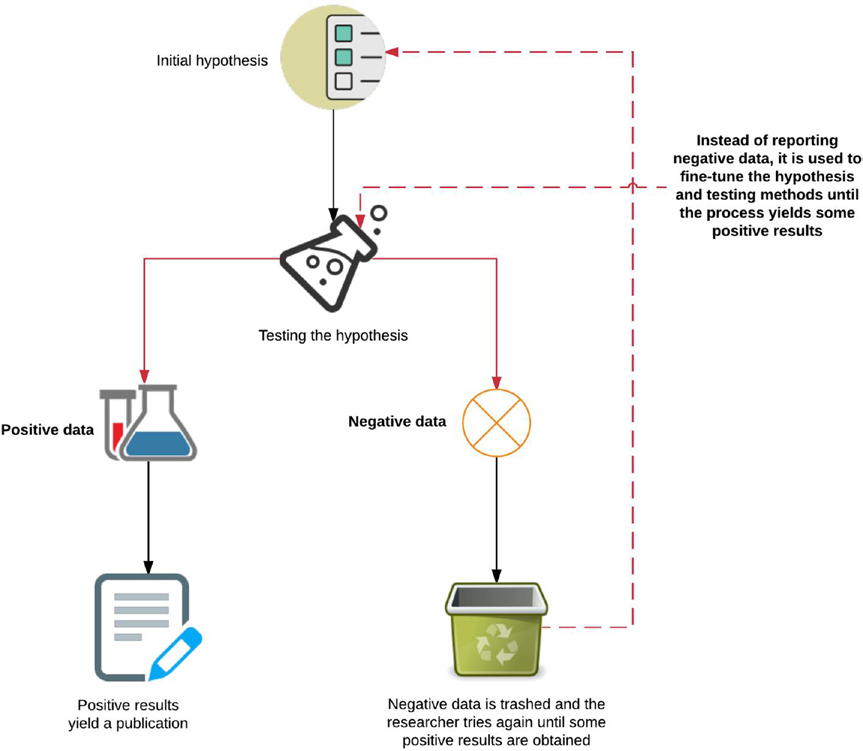
Figure 8-1 provides a very simplified overview of an erroneous research method for dealing with positive and negative data resulting from the pressures in academia. Replication is sacrificed in pursuit of highly demanding and attractive drug targets, which ultimately do not translate well into clinical trials and lead to more economic waste.
112
Chapter 8 ■ BloCkChain in SCienCe
Figure 8-1. Overview of positive and negative data in the context of publishing a study The flowchart in Figure 8-1 is a simple demonstration of hypothesis testing that leads to publication of “flukes” that are nonreplicable in translational research or scaled clinical trials. Due to the nature of publishing in academic journals, positive data usually imply that you are done. Most researchers will stop here, and not bother to follow up with any appreciable fraction of all the data that were collected or generated while conducting the experiments. This could include potential negative data regarding an avenue of thought that did not work, or information that was omitted due to feedback from reviewers.
Once a research paper has been accepted, the authors have no further incentive to release more data or put in more time to clean up and make other results available. This turns out to have some detrimental consequences, which we discuss later in the chapter.
These trends have been observed by journals internationally and they are beginning to take some action. A plethora of new initiatives are raising the standards for the data that can be included in a publication and the design considerations that must be fulfilled to ensure replication. Let’s talk about three of those efforts here.
113
Chapter 8 ■ BloCkChain in SCienCe
• Minimum publishing standards: Print journals have specific requirements for space where only a certain number of pages can be allocated to each section of a
research paper. In such scenarios, researchers focus more on making bold claims
and showing data that provide evidence for their conjectures. Usually, this comes
at expense of shortening the methods section that provides instructions for other
researchers to follow to replicate an experiment. Recently, most journals have
moved online and space is less of an issue, although supplemental materials are
still lacking in quality even when they are made available. BioMed Central has
released a checklist of minimum standards that must be met before a paper can
be published. The purpose of this checklist is to provide a level of standardization so that researchers can write papers with specific criteria in mind to enhance
reproducibility. If all the standards are met, there is a high likelihood that a
published study can be replicated to a greater degree.
• Data Discovery Index: One of the major problems mentioned earlier was the lack of incentives for researchers to make supplemental data available. The National
Institutes of Health (NIH) has sought to create a new measure to credit researchers
for uploading additional experimental data called the Data Discovery Index (DDI).
This is a citable data repository where researchers can make additional data points
available related to their studies. For academic researchers, a huge incentive is
to elicit additional citations for their work, which in turn becomes a measure of
impact for a published study. By making the database citable, NIH created this
new incentive for researchers to dedicate additional time and resources to upload
unpublished databases.
• Reproducibility Project: Cancer Biology: The Center for Open Science in collaboration with Science Exchange will be looking at high-impact studies in cancer biology from
2010 to 2012 and replicating each one with help from members of Science Exchange.
Full-length reports on the attempts at replicating experiments, discovering drug
targets, and more will be openly made available along with detailed methods. This
project is being done in two phases. The first phase culminates in a registered report that documents standardized protocols to carry out certain experiments. The second
phase involves one of the member institutes of Science Exchange conducting the
experiment using the registered report and documenting the results. Ultimately,
both the reports and data will be peer-reviewed by reviewers at the eLife journal and made available online.
These three initiatives are examples of a large-scale coordinated effort to enhance reproducibility, and many more are on the horizon. So far, we have discussed the problems in the academic environment leading to differing treatment of negative and positive data, the core of reproducibility crisis, and the difficulties that arise as a result. Next, we begin talking about the more serious consequences of data manipulation in the case of drug trials. The data points from clinical trials decide the fate of medications that will affect thousands of lives. Obtaining all relevant data is crucial not only for accurately prescribing medication, but also to avoid pitfalls and avenues already tackled in the past.
■ Note Dr. Ben Goldacre gave a teD talk in which he told a story of the drug lorcainide, released in 1980s.
it was meant to be an anti-arrhythmic drug that could prevent abnormal heart rhythms in people who have had heart attacks. a small clinical trial was conducted in fewer than 100 patients, and unfortunately ten of them died. the drug was regarded as a failure and commercial development stopped. the data from this failed clinical trial were never published. over the next few years, other drug companies had similar ideas for 114
Chapter 8 ■ BloCkChain in SCienCe
anti-arrhythmic drugs that were brought to market. it is approximated that 100,000 people died because these new drugs also caused an increased instance of death. in 1993, the researchers who conducted the original 1980 study came forth and wrote an apology mentioning that they attributed the increased death rate to chance in the initial trials. had the data from this failed trial been published, however, they could have provided early warnings and prevented future deaths. this is just one example of the very serious consequences of publication bias. We tackle a generalized version of this scenario in the next section.
Clinical Trials
We have already described a few complications that arise due to flawed data reporting from clinical trials, and here we begin outlining a potential solution. In this section, we focus on three specific issues and provide a use case for integration blockchain technology in each one.
• Trial registration: Registering clinical trials when they begin, providing timely updates, and depositing the relevant results in a public database is crucial for
offering clinicians choices in prescribing new medication to patients for whom the
standard drugs aren’t effective. Even though large-scale clinical trials involving
human participants should be registered, more often than not, these trials remain
missing in action. The only indications of data coming from the unregistered trial are a publication or perhaps a few papers that contain experiments and results highly
tailored toward proving the effectiveness of the candidate drug being proposed. This type of publication bias can mislead clinicians in a dangerous manner; therefore,
we need to incentivize investigators to send regular updates from registered clinical trials on progress and any relevant clinical protocols.
• Comparing drug efficacies: Today in most clinical settings, multiple drug options are increasingly becoming available to clinicians, but there is often a lack of
evidence from head-to-head clinical trials that allows for direct comparison of
the efficacy or safety of one drug over another. Computational models allow for
parallel processing of large data sets in a type of analysis called mixed treatment
comparisons (MTCs). These models use Bayesian statistics to incorporate available
data for a drug and generate an exploratory report on the drugs compared. This can
become the foundation for automated comparisons, as more data are liberated from
unpublished or unavailable information silos.
• Postprocessing: In some cases, when a trial is registered, and it does provide some supplemental data that goes along with a publication, the registry acts more like
a data dump than an organized data deposition. Recently, we have seen more
carefully prepared and published postanalysis summaries, but this is often an
exception, not the rule. The key here is that once clinical-trial data are linked up to the blockchain, they become available to be included in an automation workflow.
Now postanalysis summaries and data can be generated by an algorithm rather
than a person. A universal back end for storage of data can foster the development
of front-end clients that read the blockchain and, using the appropriate public–
private key pair, download the appended data from an external source and locally
do the postprocessing. After that, the summary reports can be appended back to the
blockchain.
115
Chapter 8 ■ BloCkChain in SCienCe
■ Note Soenke Bartling and some collaborators in heidelberg have been working relentlessly on open-science innovation using blockchain technology. recently, they founded a think tank called Blockchain for Science to accelerate the adoption of blockchain technology in open science. the interested reader can find more on their web site at blockchainforscience.com.
Let’s start talking about a viable solution to making clinical trials more transparent using the blockchain.
More specifically, making the data from clinical trials available to the blockchain will be done with the implementation of colored coins. The scripting language in Bitcoin allows for attachment of small amounts of metadata to the blockchain. Colored coins are a concept that leverages the blockchain infrastructure to attach static metadata that can represent assets with real-world value. We use colored coins as a metric to introduce scarcity and incentivize upload of additional data, regular updates, and so on. Before we dive more into colored coins, let’s look at what makes them special. There are three essential components.
• Coloring scheme: The encoding method by the colored coin data is encoded or decoded from the blockchain.
• Asset metadata: This represents the actual metadata attached to a colored transaction that gets stored in the blockchain. We go over an example of it later. The new colored coins protocol allows for the attachment of a potentially unlimited
amount of metadata to a colored transaction, by using torrents that provide a
decentralized way to share and store data.
•
Rule engine: In the past, the metadata just contained static information added to colored coins. Recently, however, a new rules section has been added that encodes an extra
layer of logic supported by our rule engine that unlocks smart contracts’ functionality to colored coins. Currently four types of rules are supported, as discussed later.
Here’s the generalized syntax for the metadata that can be added to a colored transaction:
{
metadata: {...Static data goes here...},
rules: {...Rule definitions go here...}
}
There are two rules from the rule engine that we will be using in our solution: the expiration rule and the minter rule. The expiration rule is used to loan an asset and it dictates the life span of an asset. After expiration, the asset returns to the last output that had a valid expiration. The minter rule grants a recipient permission to issue more of the same asset. Therefore, the minter receiving colored coins can further issue more colored coins to others on the network. Both rules play an important role for introducing scarcity in this instance of blockchain economics. What role does scarcity play? To understand this, we need to look at two players in this scenario: a holder and a minter. A holder is another rule from colored coins that dictates which address can hold an asset, and we have already described a minter.
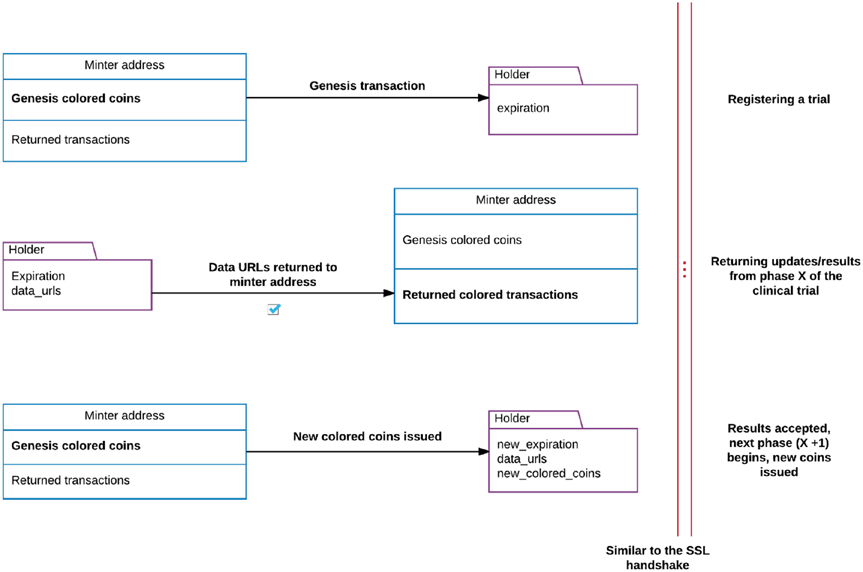
Figure 8-2 depicts the interaction between a researcher registering a clinical trial, providing updates, and a minter acknowledging reception of the updates, followed by a request to continue the next phase of the trial. Let’s walk through Figure 8-2 step by step. The clinical trial begins with our researcher registering the trial, which initiates a genesis colored transaction from the minter to the holder (our researcher). This transaction comes with an expiration rule attached, and this in a sense is the deadline for one of the several phases related to a given clinical trial. The researcher must send a colored transaction back to the minter, with URLs to metadata containing updates or new data. When the minter receives this transaction, an evaluation is performed on whether the asset was expired, and the result is exported. We return to this result in the next section. After this return transaction, the minter issues more colored coins to the holder for the 116
Chapter 8 ■ BloCkChain in SCienCe
next phase, and the cycle repeats. Each phase of the trial results in more data URLs being appended to the metadata sent by the holder as a sign of continuous updates.
■ Tip the rules engine of colored coin protocol is also a part of the metadata not stored directly on the blockchain, but instead it is stored in plain JSon format using torrents. torrents provide a decentralized mechanism to share data, and make it possible for rules to interact with objects outside of the blockchain.
We have abstracted the minter here as an oracle, but the actual implementation would involve a hybrid of an automated evaluator and smart contract.
The entire process visualized in Figure 8-2 can be considered analogous to the SSL handshake that forms the foundation of sure server–client interaction and symmetric encryption in our browsers. Perhaps in the future, one can extrapolate; if this type of interaction becomes common, it could become a feature of the colored coin wallet. The evaluation component of the minter address can become either a specialized wallet or a new client, similar to new protocols being included in a browser.
Figure 8-2. Interactions between a minter and a holder
This process can create artificial scarcity by imposing the expiration rule. The holder (researcher) has to return a colored transaction with the data URLs corresponding to the update. The minter performs an evaluation on the state of the holder and then acknowledges the receipt of updates. New coins are issued for the next cycle of updates and the whole cycle begins anew. The evaluator result is exported and will be used to build a reputation system that we discuss shortly.
117
Chapter 8 ■ BloCkChain in SCienCe
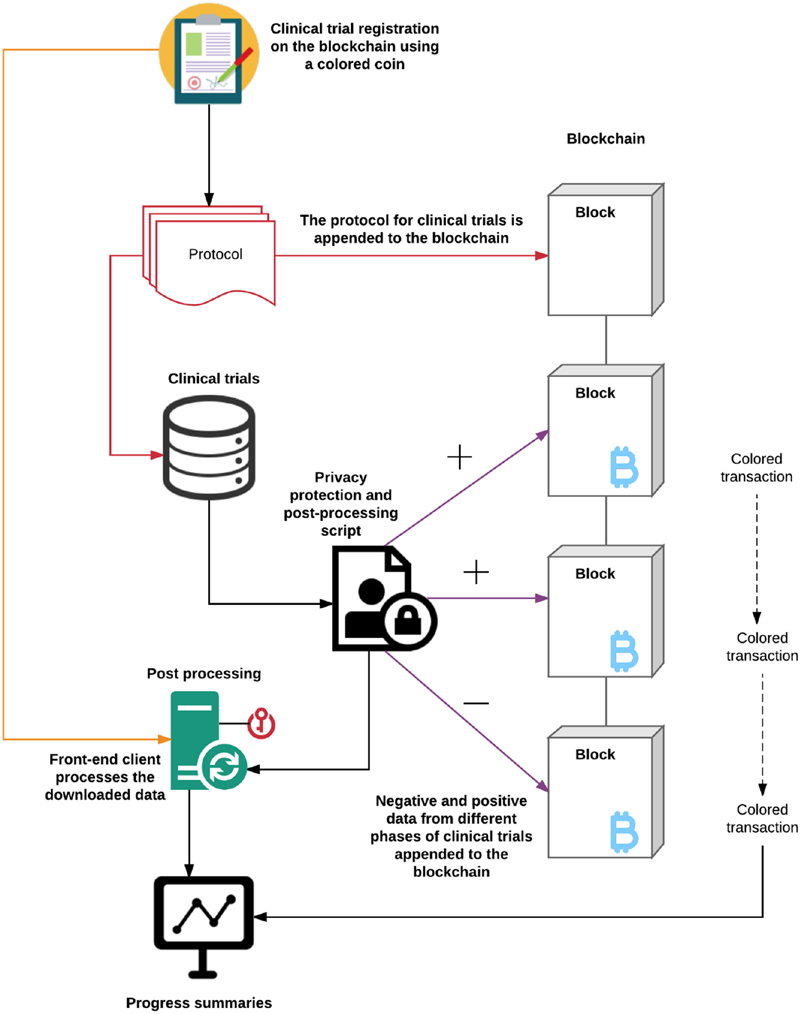
Now that we have discussed the colored coin interactions, let’s take a look at the entire clinical trials system in Figure 8-3.
Figure 8-3. Summary of blockchain integration into clinical trials workflow 118
Chapter 8 ■ BloCkChain in SCienCe
The process begins with the registration and a proposed summary of what the clinical trial will entail, the methods being used, and what data or results can be expected. The summary information along with the approved protocol are appended to the blockchain before the trial begins. This completes the registration process. Colored coins and the rules engine are used to manage updates from researchers. These updates are appended to the blockchain after going through a light privacy protection check. Once the clinical data are on a common back end, the most important benefit is perhaps the shift of focus from back-end clients that hold databases to simply developing front-end clients that can read the blockchain. The management of data will happen automatically within the blockchain; all we need is a mechanism to read the tags or breadcrumbs left over in the metadata to know what to pull from an external location for further processing.
An example of this case is the postprocessing unit shown in Figure 8-3. This unit contains the appropriate public–private key pair and permissions to read the blockchain and access the external locations. The same script that appended data updates to the blockchain also contains a segment for postprocessing that tells the postprocessing unit how to integrate data from various third-party locations into one local collection.
After that, postanalysis statistical methods are used to determine the quality of the data appended and an automated report can be generated that summarizes the progress of the trial at given intervals. The intervals at which data updates should be required from researchers, along with instructions on how to process those data once made available are coded in a script, made available to the postprocessing unit.
Reputation System
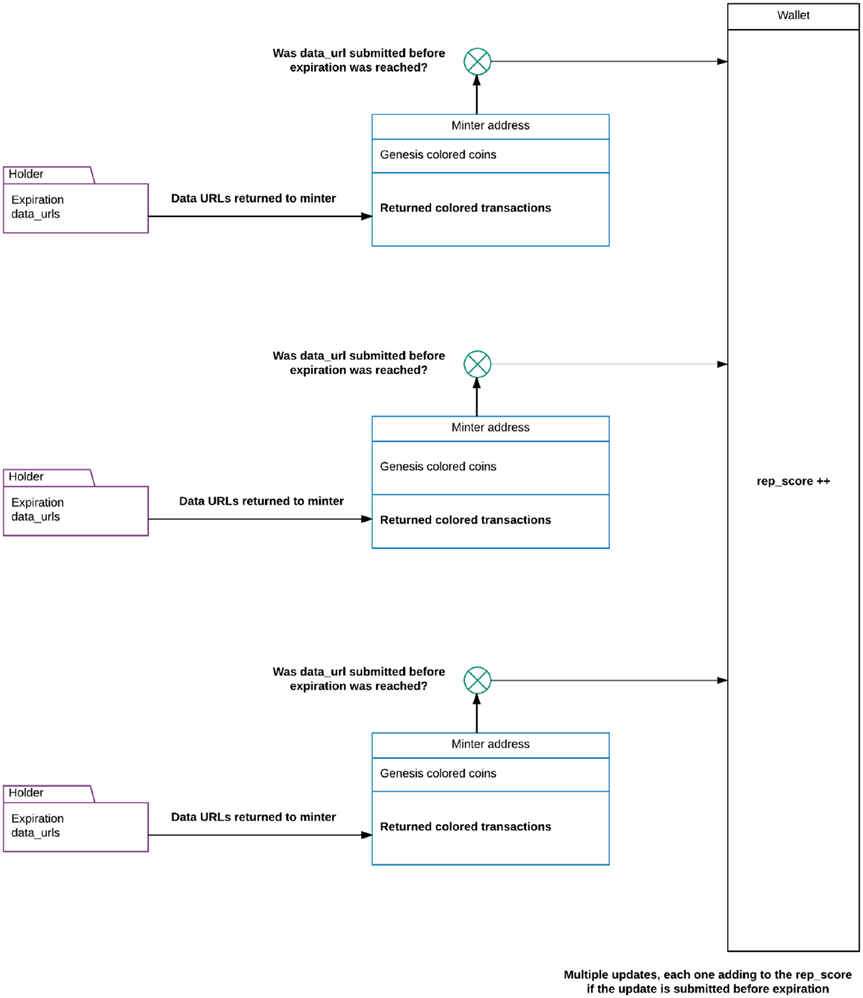
Let’s revisit the notion of scarcity. It was crucial for us to build the clinical trials system, however, the introduction of colored coins with the expiration rule also allows us to build another component, the reputation system. The premise of the reputation is simply tracking adherence to the expiration rule. Recall that we built an export feature in the evaluator function and here we can use the export as a counting mechanism to reward researchers (or holder addresses in the colored coin protocol) who have been proactive in sending periodic updates. In a practical application, this export counter would become added to the metadata by the minter after periodic updates have been established. From here, establishing reputation is a straightforward task: A higher export counter corresponds to a better reputation.
It is important to note that for our clinical trials system, reputation simply emerged as a property of the design, but it has some far-reaching implications concerning reproducibility. High reputation indicates the commitment of an institution or a research group toward quality control. Once a reputation mechanism is implemented network-wide on a blockchain, it can be referenced externally: Third-party services can request the reputation score associated with a particular colored wallet. This can be as simple as an API call to return the rep_score of a wallet. Why would this be useful? Earlier in our discussion, we mentioned the DDI, and here we want to expand the notion of DDI from just being a data repository to a repository with rep_score tags. This can provide another layer of granularity into DDI: a tag of reputation scores (high or low) on data sets linked to clinical trials that are available to the public. Keep in mind that within this design, all the data from clinical trials or updates reside in the DDI repositories; however, the rep_score lives in the blockchain metadata through colored transactions. Figure 8-4 describes the sequential evaluation happening with each periodic update and the incremental addition of reputation in rep_score.
119
Chapter 8 ■ BloCkChain in SCienCe
Figure 8-4. Overview of rep_score increasing with each periodic update The evaluator function checks for an expiration rule and if the colored transactions made by the holder contain the URLs corresponding to updates in the metadata. If those two conditions are met, the rep_score is updated for the holder’s wallet. This slow increase allows for the reputation to build over time, and the rep_score parameter can be referenced in a blockchain agnostic manner from external services. API calls can become the default manner of attaching an up-to-date rep_score to databases deposited at DDI.
120
Chapter 8 ■ BloCkChain in SCienCe
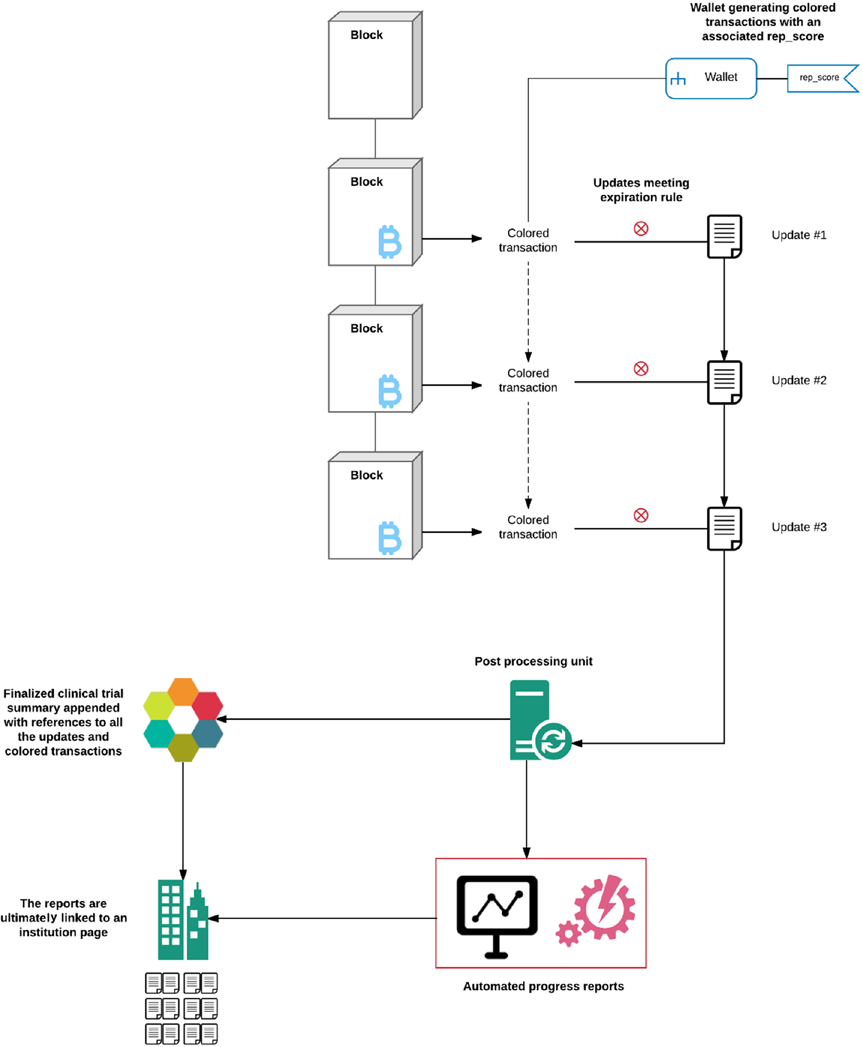
Now that we have a better understanding of the rep_score mechanism, let’s look at the complete reputation system. Figure 8-5 provides a comprehensive depiction of a reputation system and its consequences for the members network-wide.
Figure 8-5. The reputation system
121
Chapter 8 ■ BloCkChain in SCienCe
It begins with the blockchain recording colored transactions happening between the minter and holder roles from colored coin protocol. These colored transactions happen each time the holder provides an update, and the minter evaluates it. After the initial update, the minter sends a rep_score as a part of the returned colored transaction to carry on the update process for a clinical trial. The reputation now gets amended to the metadata with each exchange and the rep_score gets revised each time. This score can eventually become an attribute of the holder’s wallet, and in this manner, it can be referenced externally from the blockchain. The postprocessing unit becomes important after the clinical trial has matured to generate enough updates that can be compiled in one comprehensive overview. The purpose of this unit would be to automatically perform quality control statistical calculations and share the updates following instructions in a script added to the blockchain in the beginning of the trial. In a similar fashion, the postprocessing unit will compile a final summary and attach that to the institution’s page, along with all the updates shared from the clinical trial.
■ Note it must be noted that postprocessing and data storage are all functions done off the blockchain. no calculations or data manipulations are performed on the blockchain. We want to limit the blockchain-executable code as much as possible to only the necessary primitives. the only tools that interact with transactions or metadata on the blockchain are in place to update the distributed state of a variable or parameter.
Pharmaceutical Drug Tracking
The final use case in this chapter covers tracking pharmaceutical drugs via a supply-chain management framework. Prescription drug monitoring programs are an essential element for controlling drug shopping.
The Mayo Clinic defines drug shopping as a patient obtaining controlled substances (most often narcotics) from multiple health care practitioners without the clinician’s knowledge of the other prescriptions. This leads to drug abuse or sale on a large scale and the Mayo Clinic attributes drug shopping to the following three factors.
• Poor timeliness of data: How often does a pharmacy or provider upload prescription data into their existing centralized system? A blockchain-based back end would
make drugs associated with all transactions available instantly to all members of the network.
• Reliability: Centralized databases have a single point of failure, as compared to the blockchain, which is decentralized by nature. The data therefore do not rest on a
single database, making them more reliable.
• Complexity of data retrieval: The current model of data retrieval and compatibility with existing hospital systems is completely broken. Hospitals often are not synced
up to the databases being used by pharmacies and updating is an arduous task.
Blockchain makes the process universal by providing a common back end to read for
external services.
In this system, when a clinician writes a prescription, the provider can check the blockchain to find the patient record for any currently active prescriptions. This can help the clinician determine whether the patient is asking for prescriptions from multiple sources or whether another family member is getting the same prescription. An active prescription from a different provider would automatically invalidate the request for a new one, and this could be encoded in the network as a double spending request. Otherwise, the transaction will go through and the pharmacy will receive a request to provide medication to the patient.
The requesting provider and patient can sign the transaction, allowing for better tracking all the way through the care of a particular patient. Although this system seems simple, it fulfills most of the requirements for 122
Chapter 8 ■ BloCkChain in SCienCe
a Drug Supply Chain Security Act (DSCSA) compatible system that can be implemented across providers.
There are some efforts underway to control the opioid overprescription epidemic by major blockchain players such as IBM and Deloitte blockchain lab. Recently, some new startups have sprung up focused solely on pharmaceutical drug tracking using the blockchain.
Even though supply-chain management fits the blockchain infrastructure most closely and out of the box, this field is very new and the technology is immature. The future of drug tracking and open science looks much more promising with new technologies enabling layers of communication that were never possible before. Blockchain, if nothing more, has been an immense catalyst of new innovation in open scientific inquiry and discourse.
Prediction Markets and Augar
In this chapter, we talked about reputation being a key parameter in holding researchers accountable for providing additional scientific data that can enhance the reproducibility of published studies. A crucial challenge to achieving this goal is the alignment of incentives for researchers to gain benefits from making their data available. Let’s look at some current efforts in academia that would make integration of a blockchain in existing infrastructure more feasible.
In 2015, a large-scale crowdfunded replication effort was underway to verify key findings from 100
psychology studies. Before this effort concluded, some of the researchers filled out a survey for 44 studies indicating the likelihood they thought that the study’s main finding would be successfully replicated. The same researchers also played a betting game: They were given $100 USD to buy and trade contracts in the ongoing replication efforts. Each contract would pay $1 if the key finding were to be successfully replicated.
Data from the survey and the betting games was collected and published in Proceedings of the National Academy of Sciences (PNAS). It turns out that the survey predictions were about as accurate as a coin flip. However, if the researchers engaged in a betting market on the same question, the data gave a good prediction (with approximately 71% accuracy) of which studies would hold up if replicated. The market approach might have been more accurate than the survey for two reasons: First, there were monetary incentives to make the best bet, and second because the market enables people to learn trends from other players and to adjust their bets. The authors of the PNAS study suggest that prediction markets can be used to decide which studies should be prioritized in replication efforts due to their uncertainty. They warn that prediction markets will not reliably predict which individual findings are accurate, but they can be used to estimate the credibility of current findings and make an ordered queue of studies to be replicated.
Setting up a prediction market would require a platform, and that’s where Augar comes in. Augar is a decentralized prediction market platform that runs on the Ethereum blockchain. The underlying exchange of value on Augar is REP tokens or reputation. REP is used by referees (also known as reporters) to report event outcomes on the platform, and Ether is used by other users to place bets on markets.
On Augar, the prediction market works in two phases: Forecast and reporting. Initially, a user supplies some funds to creates a prediction market to address an event outcome or question, and the forecasting period begins. Other users place their bets during this period and the event matures. After the event has happened, the reporting period begins. The reporters act as oracles for the network and submit their answers or outcome. After a sufficient number of answers have been received, a consensus on the event is generated. The reporters who submitted the correct outcome are rewarded with reputation for their service, and the users who made a bet on the correct outcome are paid out in Ether.
The betting games played by researchers in the PNAS study can be repeated on a platform like Augar at a larger scale. More work remains to be done before Augar can be used for prediction in replication studies, but the platform has all the required features to serve large-scale reproducibility efforts.
123
Chapter 8 ■ BloCkChain in SCienCe
Summary
This chapter started with a broad description of the reproducibility problem and its serious economic consequences in evidence-based sciences. Then, we moved into discussing the current solutions and their shortcomings in the science community. After that, we described the idea of building reputation systems using blockchain and covered three use cases: clinical trials, reputation networks, and finally pharmaceutical tracking of drugs from manufacturing. All the use cases highlighted the strengths of blockchain in tracking and accountability over traditional methods.
124