Being pseudorandom means that the hash value returned by a hash function changes unpredictably when the input data are changed. Even if the input data were changed only a little bit, the resulting hash value will differ unpredictably.
To put it differently, the hash value of changed data must always be a surprise.
It should not be possible to predict the hash value based on the input data.
One-Way Function
A one-way function does not provide any way to trace its input values by its outputs. Hence, being a one-way function means that it cannot be used the other way around. To put it differently, it is impossible to recover the original input data based on the hash value. This means that hash values do not tell you anything about the content of the input data in the same way as an isolated fingerprint does not tell you anything about the person whose finger created it. One-way functions are also said to be noninvertible.
Collision Resistant
A hash function is called collision resistant if it is very hard to find two or more distinct pieces of data for which it yields the identical hash value. Or, to put it differently, if the chance to receive an identical hash value for distinct pieces of data is small, then the hash function is collision resistant. In this case, you can consider the hash values created by the hash function as being unique and hence being usable to identify data. If you obtained an identical hash value for different pieces of data, you would face a hash collision. A hash collision is the digital equivalent to having two people with identical fingerprints. Being collision resistant is mandatory for hash values to be usable as digital fingerprints. How collision resistant hash functions work internally is beyond the scope of this book, but you can be assured that huge effort has been spent on reducing their risk to produce hash collisions.
Trying It Out Yourself
This section will help you become comfortable with applying hash functions by guiding you through a simple example. For this purpose, I refer to the accompanying website that provides a tool for creating hash values of simple text data: http://www.blockchain-basics.com/HashFunctions.html.
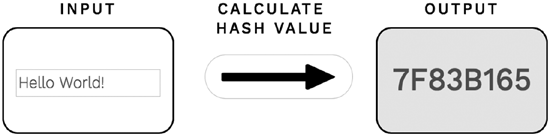
When you open that webpage in your Internet browser, you will see an input box and an output box, as shown in Figure 10-1. Type the text Hello World!
in the input box on the left-hand side and click the button with the label
“Calculate Hash Value” located below the text field. Make sure that you type Hello World! exactly in the input box, otherwise you will get results that differ from those shown in Figure 10-1.
74
Step 10 | Hashing Data
Figure 10-1. Calculating hash values of a short text
As a result of clicking the button, the output box on the right-hand side will present the hash value of the input text calculated with four different hash functions. Hash values are often regarded as hash numbers since they use not only the digits 0 to 9 but also the letters A to F, which represent the values 11 to 16 in order to express numerical values. Those numbers are called hexadecimal numbers. Computer scientists love them for reasons I do not want discuss here. Notice that the hash values differ due to the different implementation details of the hash functions that produce them. These values are taken for granted, since we do not want to lose ourselves in the wide topic of implementation of hash functions.
Cryptographic hash values are quite long and therefore hard to read or to compare for the human eye. However, in the course of this step, you will compare different ways of hashing data, which involves reading and comparing hash values. Doing so with cryptographic hash values will quickly become a tedious task. Hence, for didactical reasons, I use a shortened version of the SHA256 cryptographic hash value in the remainder of this step. You can reproduce all hash values by using the tool provided on the accompanying website: www.blockchain-basics.com/Hashing.html.
When you open that website in your Internet browser, you will see an input box for simple texts, a button with an arrow that points to an output box, as shown in Figure 10-2. When you click the button with the arrow, the output box will present the shortened hash value of the text provided in the input box.
Figure 10-2. Calculating the shortened hash value of a text
Blockchain Basics
75
Patterns of Hashing Data
So far you have learned that a piece of data can be used as input for a hash function, which in turn yields the hash value of that data. This implies that each independent piece of data has its own unique cryptographic hash value. But what would you do if you were asked to provide one single hash value for a bunch of independent pieces of data? Remember, hash functions only accept one piece of data at a given time. There is no hash function that accepts a bunch of independent data at once, but, in reality, we often need one single hash value for a large collection of data. In particular, the blockchain-data-structure has to deal with many transaction data at once and requires one single hash value for all of them. How do you deal with this task?
The answer is to utilize one of the following patterns in applying hash functions to data:
• Independent hashing
• Repeated hashing
• Combined hashing
• Sequential hashing
• Hierarchical hashing
Independent Hashing
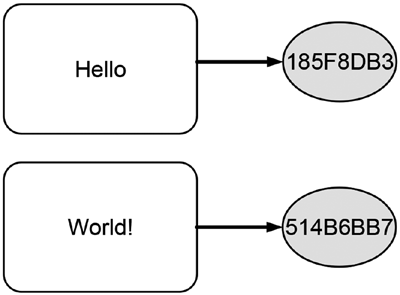
Independent hashing means applying the hash function to each piece of data independently. Figure 10-3 illustrates this concept by calculating the shortened hash value of two distinct words separately.
Figure 10-3. Schematic illustration of hashing different data independently
76
Step 10 | Hashing Data
The white boxes that each contain a word represent the data to be hashed and the gray circles exhibit the corresponding hash values. The arrows that point from the boxes to the circles schematically illustrate the transformation of data into hash values. As one can see in Figure 10-3, the distinct words yield different hash values.
Repeated Hashing
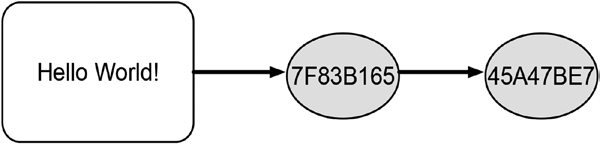
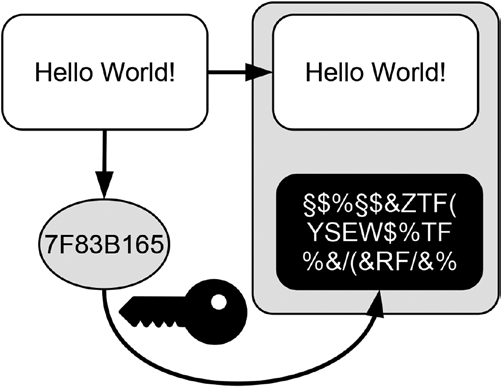
You have learned that hash functions transform any arbitrary piece of data into a hash value. A hash value itself can be considered a piece of data. Hence, it should be possible to provide a hash value as input to a hash function and calculate its hash value too. And this in fact works! Repeated hashing is the repeated application of a hash function to its own outcome. Figure 10-4
illustrates the concept by calculating the shortened hash value repeatedly.
The text Hello World! yields the hash value 7F83B165, which in turn yields the shortened hash value of 45A47BE7.
Figure 10-4. Calculating hash values repeatedly
Combined Hashing
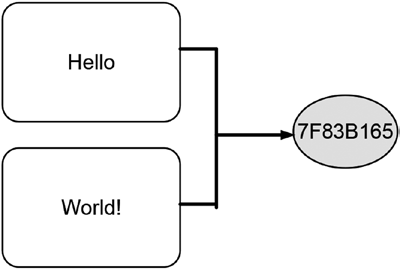
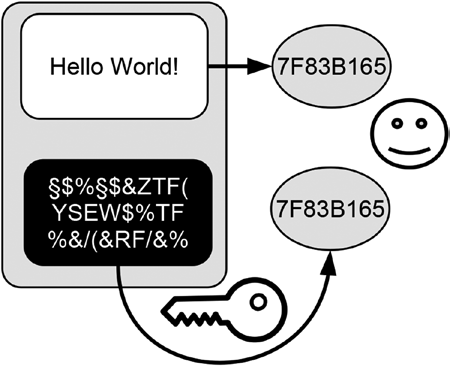
The goal of combined hashing is to get a single hash value for more than one piece of data in one attempt. Combining all independent pieces of data into one piece of data and calculating its hash value afterward is the way to achieve this. This is in particular useful if you want to create one single hash value for a collection of data that is available at a given time. Since combining data costs computing power, time, and memory space, combined hashing should only be used when the individual pieces of data are small. Another drawback of combined hashing is that the hash values of the individual pieces of data are not available since only the combined data are handed over to the hash function.
Figure 10-5 depicts the concept of combined hashing. The individual words are first combined into one word with a letter space between them and the resulting phrase is hashed afterward. The resulting hash value shown in Figure 10-5
is consequently identical to the first hash value in Figure 10-4. Note that the
Blockchain Basics
77
hash value of the combined data critically depends on the way the data are combined. In Figure 10-4, the two words were combined by writing them next to each other with a letter space between them, which consequently yields Hello World! Sometimes specific symbols such as the plus sign (+) or hashtag sign (#) are used to mark the point where the data are connected, which, as a result, influences the resulting hash value.
Figure 10-5. Combining data and subsequently calculating the hash value Sequential Hashing
The goal of sequential hashing is the incremental update of a hash value as new data arrive. This is achieved by using combined and repeated hashing at the same time. The existing hash value is combined with new data and is then handed over to the hash function in order to get the updated hash value.
Sequential hashing is in particular useful if you want to maintain a single hash value over time and update it as soon as new data arrive. An advantage of this type of hashing is that at any given point in time you have a hash value whose evolution can be traced back to the arrival of new data.
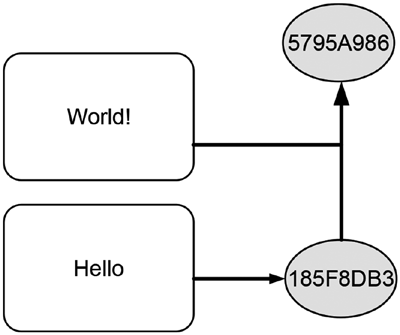
Figure 10-6 illustrates the concept of sequential hashing by starting with hashing the word Hello individually, which yields the shortened hash value 185F8DB3. Once new data represented by the word World! arrive, it is combined with the existing hash value and provided as input to a hash function. The hash value 5795A986 is the shortened hash value of the input text World! 185F8DB3.
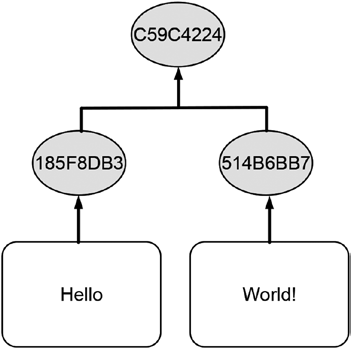
78
Step 10 | Hashing Data
Figure 10-6. Calculating hash values sequentially
Hierarchical Hashing
Figure 10-7 illustrates the concept of hierarchical hashing.
Figure 10-7. Calculating hash values hierarchically
The application of combined hashing to a pair of hash values forms a small hierarchy of hash values with a single value on its top. Similar to combined hashing, the idea of hierarchical hashing is the creation of one single hash value for a collection of data. Hierarchical hashing is more efficient because it combines hash values that are always of fixed size instead of the original data that could be of any size. Additionally, hierarchical hashing only combines two hash values in every step, while combined hashing will combine as many data as you provide in one attempt.
79
Outlook
This step was devoted to the concept of hash functions. Step 11 illustrates
how hash values are used in real life and highlights how the blockchain uses them.
Summary
• Hash functions transform any kind of data into a number
of fixed length, regardless of the size of the input data.
• There are many different hash functions that differ among
others with respect to the length of the hash value they
produce.
• Cryptographic hash functions are an important group of
hash functions that create digital fingerprints for any kind
of data.
• Cryptographic hash functions exhibit the following
properties:
• Provide hash values for any kind of data quickly
• Deterministic
• Pseudorandom
• One-way usage
• Collision resistant
• Application of hash functions to data can be accomplished
by using the following patterns:
• Repeated hashing
• Independent hashing
• Combined hashing
• Sequential hashing
• Hierarchical hashing
11
Hashing in the
Real World
A tale of comparing data and creating
computational puzzles
Step 10 introduced cryptographic hash functions and discussed different patterns of applying hash functions to data. Step 10 may have appeared to be a dry intellectual exercise, but it is actually of highly practical relevance. Hence, this step focuses on the application of hash functions and hash values in the real world. It considers major use cases of hash functions in real life and explains the idea behind them. This step also sketches why these use cases work out as intended. Finally, this step points out where the blockchain uses hash values.
Comparing Data
Because it is the most straightforward use case of hash values, comparing data based on their hash values is considered first.
The Goal
The goal is to compare data (e.g., files or transaction data) without comparing their content piece by piece and to make comparing any kind of data, regardless of their size and content, as easy as comparing two numbers.
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_11
Step 11 | Hashing in the Real World
The Idea
Instead of comparing data by explicitly comparing their content piece by piece, you compare their cryptographic hash values.
How It Works
You calculate and compare the cryptographic hash value of all data under consideration. If all of the cryptographic hash values differ, all the data under consideration differ as well. If two or more of the cryptographic hash values are identical, their corresponding input data are also identical.1
Why It Works
Comparing data by comparing their cryptographic hash values works due to collision resistance of cryptographic hash functions.
Detecting Changes in Data
The idea of comparing data based on their hash values can be easily extended to the case of detecting changes.
The Goal
The goal is to determine whether data (e.g., a file or transaction data) that is supposed to stay unchanged was changed after a certain date or after sending it to someone or after it was stored in a database.
The Idea
Comparing the cryptographic hash value of the data under consideration that was created in the past with a newly created cryptographic hash value of the same data is the key in identifying changes. If both hash values are identical, the data were not changed after the time at which the old hash value was created.
How It Works
You create the cryptographic hash value of the data that are supposed to stay unchanged. When you need to verify whether the data were changed at a later time, you create the cryptographic hash value of the data again. You then compare the newly created hash value with the hash value that was created 1Tsudik, Gene. Message authentication with one-way hash functions. ACM SIGCOMM
Computer Communication Review 22.5 (1992): 29–38.
83
in the past. If both hash values are identical, the data were not changed after the first hash value was created. Otherwise, the data have been changed in the meantime. The same idea can be applied when sending data to someone.
If you create the hash value of the data before they are sent and the receiver creates the hash value of the data he or she receives, both the sender and the receiver compare both hash values. If both hash values are identical, the data were not altered in the course of the transfer.
Why It Works
Detecting changes in data is actually a process of comparing data with themselves before and after certain events, such as lapses of time, storing to or retrieval from a database, or sending them through a network. Detecting changes in data that are supposed to stay unchanged works due to collision resistance of cryptographic hash functions.
Referring to Data in a Change-Sensitive
Manner
Comparing data and detecting changes based on their hash values can be considered basic use cases of hash values. A slightly more advanced application case of hash values is hash references, which are introduced in the following.
The Goal
The goal is to refer to data (e.g., transaction data) that are stored somewhere else (e.g., on a hard disk or in a database) and ensure that the data have remain unchanged.
The Idea
The idea is to combine the cryptographic hash value of the data being stored with information about the place where the data are located. If the data were changed, both pieces of information would no longer be consistent and hence the hash reference would become invalid.
How It Works
References to data are the digital equivalent to cloakroom tickets. Cloakroom tickets point to the physical location at which your jacket is stored in the cloakroom. You use the cloakroom ticket for retrieving your jacket later on. References to data in computers work the same way: they are pieces of data that refer to other data. Computer programs use references in order to
84
Step 11 | Hashing in the Real World
remember the place where the data have been stored and to retrieve them later on. Hash references are a specific kind of reference that utilize the power of cryptographic hash values. For simplicity, you could think of hash references as cloakroom tickets that display hash values instead of ordinary numbers.
Hash references refer to other data, and they additionally verify that the data being referred to were not changed since the reference was created. In the case where the data being referred have been changed, the reference no longer allows retrieval of the data. In this case, the hash reference is deemed broken or invalid. This is similar to having a cloakroom ticket that points to a coat hook that no longer carries your jacket. In this case, the cloakroom attendant can no longer hand over your jacket.
The whole idea of hash reference is to protect its users from retrieving data that have been changed accidently due to technical errors or intentionally by someone else without informing you about that. Hence, hash references are used in all occasions where data are supposed to stay unchanged once created.
A Schematic Illustration
The blockchain heavily depends on hash references. Hence, understanding them is crucial for understanding the blockchain and for comprehending the following steps of this book. For this reason, the following three figures serve two purposes: First, they schematically illustrate the functioning of hash references. Second, they introduce a pictorial representation of hash references that is used in the following steps when illustrating the functioning of the blockchain-data-structure.
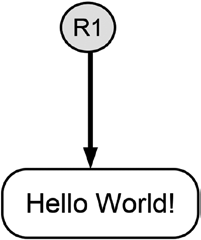
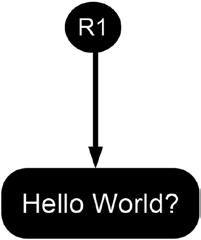
Figure 11-1 illustrates the functioning of hash references schematically by presenting a valid hash reference. The gray circle labeled R1 represents a valid hash reference. The white box represents some data that are supposed to stay unchanged. The arrow that goes from the circle to the box depicts the functioning of the hash reference. The arrow points from the reference to the data it refers to.
Figure 11-1. Schematic illustration of a valid hash reference
Blockchain Basics
85
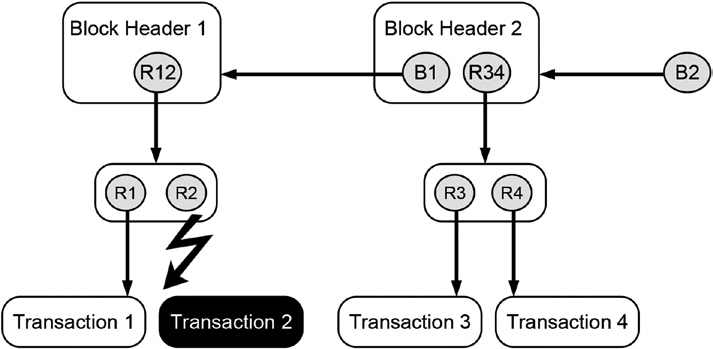
Figure 11-2 illustrates the symbolic representation of a broken or invalid hash reference.
Figure 11-2. Schematic illustration of an invalid hash reference The black box containing a modified greeting represents data that were altered after the reference was created. The gray circle still represents the originally created hash reference. The jacked arrow that points from the circle to the altered box highlights that the hash reference R1 is broken, it no longer allows access to retrieve the data because they have been changed in the meantime.
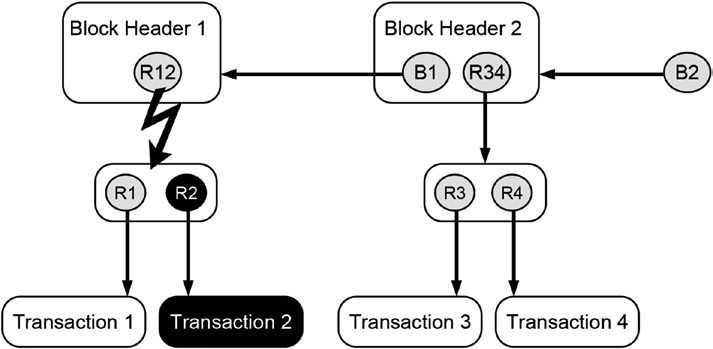
Figure 11-3 illustrates the situation when a new hash reference was created after the data were changed. This situation is depicted by a black box representing altered data, a black circle representing a newly created hash reference, and the straight arrow pointing from the circle to the box.
Figure 11-3. Schematic illustration of a newly created hash reference after altering the data being referred
Step 11 | Hashing in the Real World
Why It Works
The key point of hash references is the fact that they utilize cryptographic hash values, which can be seen as unique fingerprints of data. Hence, it is very unlikely to have two different pieces of data that have an identical hash value.
As a result, a broken hash reference is considered to be evidence that the data were altered after the hash reference was created.
Storing Data in a Change-Sensitive Manner
The idea of referring to data based on their hash values can be extended further. A natural extension of that idea is storing data in a change-sensitive manner.
The Goal
The goal is to store a large amount of data e.g., transaction data that are supposed to stay unchanged. Any changes to these data are to be detected quickly and easily.
The Idea
Cloakroom tickets point to coat hooks that carry jackets. This is simple and straightforward. But what precludes you from putting a cloakroom ticket in the pocket of another jacket and storing that second jacket in the cloakroom as well? As a result, the latter cloakroom ticket points to a jacket that contains a cloakroom ticket, which in turn points to another jacket. Actually you can create long and complicated chains of jackets that have cloakroom tickets in their pockets, which point to other jackets, which also have a cloakroom ticket in their pockets, and so on and so forth. In a similar fashion, one can store data together with hash references that point to other data, which in turn store hash reference that refer to further data, and so on and so forth.
If any of the data or hash references is changed after their creation, all the hash references are broken. Since broken hash references serve as evidence that data were changed after the reference was created, the whole construct stores data in a change-sensitive manner.
How It Works
There are two classical patterns of using hash references in order to store data in a change-sensitive manner:
• The chain
• The tree
Blockchain Basics
87
The Chain
A chain of linked data, also called a linked list, 2 is formed when each piece of data also contains a hash reference to another piece of data. Such a structure is useful for storing and linking data together that are not fully available at one given point in time but instead arrive step by step in an ongoing fashion. Figure 11-4 illustrates this idea by using the symbols introduced above.
The creation of such a chain starts with the piece of data labeled Data 1 and the creation of the hash reference R1. Being the first piece of data, Data 1
does not contain any hash reference. When new data arrive, they are put together with the hash reference that points to Data 1. The hash reference R2 refers to the newly arrived data and the hash reference R1. The hash reference R3, which refers to Data 3 and the hash reference R2, is created in a similar fashion.
Figure 11-4. Data linked together in a chain-like fashion Hash reference R3 is all you need in order to access all the data in the chain in the reverse order of their arrival. The reference R3 is also called the head of the chain because it refers to the most currently added piece of data. It is important not to mix up the term “head” (that is the most currently added piece of data) with the term “header”, which will be introduced in Step 14
when we discuss the blockchain-data-structure.
The Tree
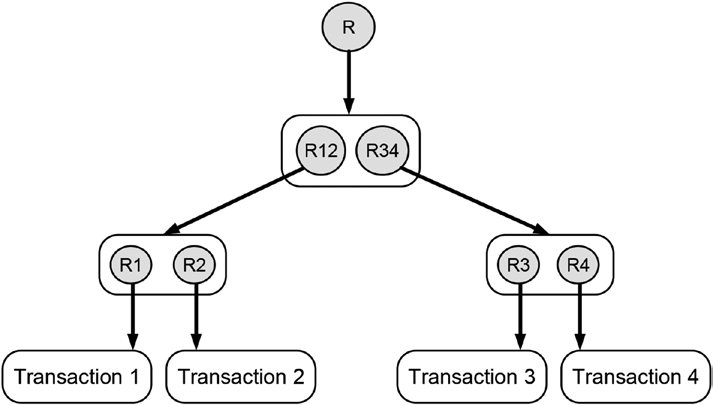
Figure 11-5 illustrates how transaction data can be linked together with hash references in a tree-like fashion.
2Cormen, Thomas H. Introduction to algorithms (3rd ed.). Cambridge: MIT Press, 2009.
88
Step 11 | Hashing in the Real World
Figure 11-5. Data linked together in a tree-like fashion Such a structure is also called a Merkle tree3 because a computer scientist named Merkle proposed it and it looks like a tree that was turn upside down.
It is very useful for grouping many distinct pieces of data that are available at the same time and to make them accessible via a single hash reference.
In order to create the tree illustrated in Figure 11-5, you start with the four transaction data represented by the boxes at the bottom of the figure. At first the hash references to the individual transaction data are created (R1 to R4), which are grouped together in a pair-wise fashion afterward. Subsequently, hash references to the pairs of hash references are created (R12 and R34).
This procedure is repeated until you eventually arrive at a single hash reference, which is also called the root of the Merkle tree (labeled R).
Why It Works
The explained data structures store data in a change-sensitive fashion because they connect and combine data with hash references. These references get broken when the data they refer to are changed after the references were created. Hence, observing a broken reference in such a construct is proof that some of the data were changed after the structure was created. Otherwise, it could be concluded that the whole construct has not been changed since it was created.
3Merkle, Ralph C. Protocols for Public Key Cryptosystems. IEEE Symposium on Security and Privacy 122 (1980).
89
Causing Time-Consuming Computations
Hash values are not only useful for making basic file operations such as comparing, referring and storing data secure and efficient. Hash values can also be used to allow computers to challenge other computers with elaborate puzzles. While this may sound a bit odd it will turn out that this usage of hash values is one of the most important concept of the blockchain.
The Goal
For reasons that will become understandable in later steps of this book, you may need to create puzzles that require computational resources in order to be solved. It should not be possible to solve these puzzles based on knowledge or data stored somewhere or by means of thinking, like an IQ test or a knowledge test. The only way to solve these puzzle is by sheer computational power and hard computational work.
The Idea
A combination lock is a specific lock that requires a unique sequence of numbers in order for it to be opened. If you do not know the sequence that opens the lock, you would systematically try all possible combinations until you eventually arrived at the unique combination that opens the lock. This procedure is guaranteed to open the lock, but it is time-consuming. Systematically trying all possible combinations has nothing to do with knowledge or intellectual reasoning. The approach of opening a combination lock is based on sheer diligence and hard work. Hash puzzles are computational puzzles that can be seen as the digital equivalent to the task of opening a combination lock by trial and error.
How It Works
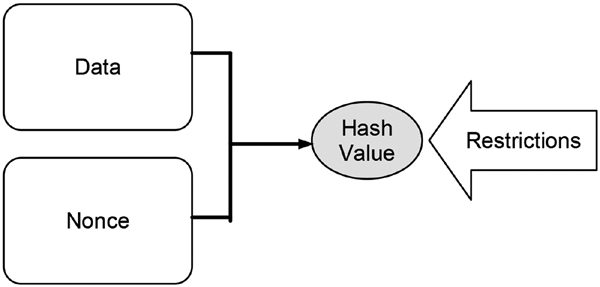
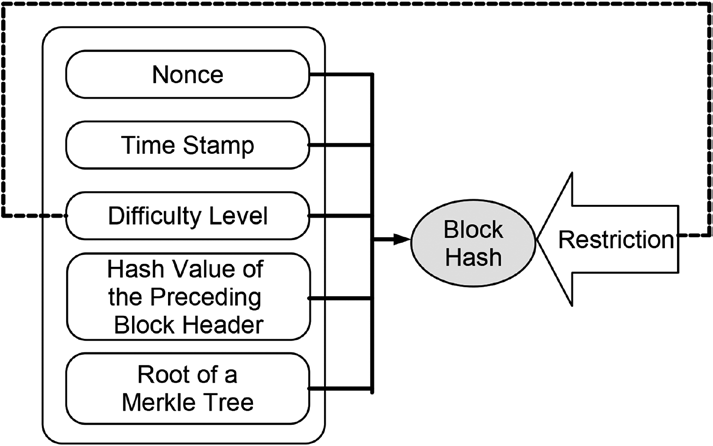
Elements of a hash puzzle are4:
• Given data that have to be kept unchanged
• Data that can be freely changed, the so-called nonce
• The hash function to be applied
• Restrictions on the hash value of the combined hashing,
also called the difficulty level
4Back, Adam. Hashcash—a denial of service counter-measure. 2002. http://www.hashcash.
90
Step 11 | Hashing in the Real World
Figure 11-6 illustrates the setting of the hash puzzle. Combined hashing is applied to the data and the nonce. The resulting hash value has to fulfill the given restrictions.
Figure 11-6. Schematic illustration of a hash puzzle
Hash puzzles can only be solved by trial and error. This requires guessing a nonce, calculating the hash value of the combined data with the required hash function, and evaluating the resulting hash value based on the restrictions. If the hash value satisfies the restrictions, you will have solved the hash puzzle; otherwise, you would continue with another nonce until you eventually solve the puzzle. The nonce that, when combined with the given data, yields a hash value that satisfies the restrictions is called the solution. You always have to present that particular nonce when claiming that you solved a hash puzzle.
An Illustrative Example
Let’s consider a real hash puzzle for illustrating its functioning. In Step 10 you saw that the shortened hash value of Hello World! is 7F83B165. But what data combined with Hello World! would yield a shortened hash value with three leading zeros? So the hash puzzle is: Find the nonce that combined with Hello World! yields a shortened hash value that starts with three leading zeros.
Let’s get our hands dirty and try some nonce. Table 11-1 shows the nonce, the text to be hashed, and the resulting shortened hash value. As you can see, the nonce 614 solves the hash puzzle, which implies that starting with a nonce 0 and incrementing sequentially by 1 you would need 615 steps to find the solution. If the restriction were to find a hash value with one leading zero, you would have solved it already after four steps, since Hello World! 3 yields a hash value with one leading zero.
91
Table 11-1. Nonces for Solving a Hash Puzzle
Nonce
Text to Be Hashed
Output
0
Hello World! 0
4EE4B774
1
Hello World! 1
3345B9A3
2
Hello World! 2
72040842
3
Hello World! 3
02307D5F
…
613
Hello World! 613
E861901E
614
Hello World! 614
00068A3C
615
Hello World! 615
5EB7483F
You can try this yourself at www.blockchain-basics.com/HashPuzzle.
html.
The Difficulty Level
Requiring the hash value to fulfill a certain restriction is the core of the hash puzzle. Hence, neither the restriction nor its description is arbitrary. Instead, the restriction used by hash puzzles is standardized so that computers can challenge other computers with hash puzzles. In the context of hash puzzles, the restrictions are often called difficulty or difficulty level, respectively. The difficulty is expressed as a natural number and refers to the number of leading zeros the hash value has to have. Hence, a difficulty of 1 means that the hash value has to have (at least) one leading zero, while a difficulty of 10 means that the hash value has to have at least 10 leading zeros. The higher the difficulty level, the more leading zeros are required and the more complicated the hash puzzle is. The more complicated the hash puzzle is, the more computational power or time are needed to solve it.
Why It Works
The functioning of hash puzzles critically depends on the fact that hash functions are one-way functions. It is not possible to solve a hash puzzle by inspecting the restrictions that the hash value has to fulfill and applying the hash function in the opposite direction afterward (i.e., going from the desired output to the required input). Hash puzzles can only be solved by trial and error, which consumes a lot of computing power and hence a lot of time and energy. The level of difficulty directly influences the number of trials needed on average for finding the solution, which in turn influences the computational resources or the time needed to find the solution.
Step 11 | Hashing in the Real World
Hash functions are deterministic and quickly produce hash values for any kind of data. Hence, once a solution is found, it is easy to verify that the data combined with the nonce indeed yield a hash value that satisfies the restrictions. If the calculated value does not satisfy the restriction, the hash function cannot be blamed because the deviation is only caused by the fact that the puzzle has not been solved.
■ Note In the context of the blockchain, hash puzzles are often called proof of work, as their solution proves that someone has done the work necessary to solve it.
Usage of Hashing in the Blockchain
Within the blockchain, hashing is used in the following instances:
• Storing transaction data in a change-sensitive manner
• As a digital fingerprint of transaction data
• As a way to incur computational costs for changing the
blockchain-data-structure
Outlook
This step explained major use cases of hash values and sketched their usage in the blockchain. The next steps will discuss in greater detail the way hashing is utilized by the blockchain.
Summary
• Hash values can be used:
• To compare data
• To detect whether data that were supposed to stay
unchanged have been altered
• To refer to data in a change-sensitive manner
• To store a collection of data in a change-sensitive manner
• To create computationally expensive tasks
12
Identifying and
Protecting User
Accounts
A gentle introduction to cryptography
Besides hash functions, the blockchain uses another base technology extensively: asymmetric cryptography. It is the foundation for identifying users in the blockchain and protecting their property. Cryptography is often considered complicated and hard to understand. Hence, this step focuses on introducing cryptography in a gentle way that is easy to comprehend and sufficient for understanding the security concept of the blockchain.
The Metaphor
Long before e-mails, facsimiles, telephones, and chat apps were invented, people used conventional mail to send messages. Along with its modern competitors, conventional mail still exists and is still used by many people.
Conventional letters are still delivered by postal employees, who deliver letters by putting them in the mailboxes of the addressees. Mailboxes functioning like trapdoors. By design, it is easy to insert a letter through the letter slot, but
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_12
Step 12 | Identifying and Protecting User Accounts
it is very hard to pull a letter out that way because taking out letters is supposed to be done only by the addressee who owns the key necessary to open the mailbox. This concept has been used for a very long time and we still use a similar concept when we send an e-mail to an e-mail address, when we send a message in the latest chat app, or when we transfer money to a bank account.
In all these cases, the security concept is based on a separation of two kinds of information: first, publicly known information that serves as an address to a trapdoor-like box; and second, private information that serves as the key for opening the box and accessing the things it contains. The blockchain applies the same concept when protecting private data. Hence, keeping this metaphor in mind may provide some guidance on your way in learning about the world of cryptography.
The Goal
The goal is to identify owners and property uniquely and to ensure that only the lawful owner can access his or her property.
The Challenge
The blockchain is a peer-to-peer system that is open to everyone. Everyone can connect and contribute computational resources or submit new transaction data to the system. However, it is not desirable for everyone to access the property assigned to the accounts managed by the blockchain. A constituting characteristic of private property is its exclusiveness. The right to transfer ownership to another account is restricted to the owner of the account who hands off ownership. Hence, the challenge of the blockchain is to protect the property assigned to the accounts without restricting the open architecture of the distributed system.
The Idea
The idea is to treat accounts like mailboxes: everyone can transfer property to it, but only the owner of the account can access the things that are collected inside. The major characteristic of a mailbox is that its location is known and hence anyone can put something in but only the owner can open it with a key. The duality of a public mailbox, on the one hand, and a privately held key,
95
on the other hand, has an equivalent in the digital world: public-private-key encryption. One uses public keys for identifying accounts to which everyone can transfer ownership, while access is restricted to those who possess the corresponding private keys. 1
A Short Detour to Cryptography
In order to help you understand cryptography, I will discuss the following aspects:
• The major idea of cryptography
• Terminology
• Symmetric cryptography
• Asymmetric cryptography
The Major Idea of Cryptography
The major idea of cryptography is to protect data from being accessed by unauthorized people. It is the digital equivalent to door locks or bank safes, which also protect their content from being accessed by unauthorized people.
Similar to locks and keys in the physical world, cryptography also uses keys to protect data.
Terminology2
The digital equivalent to closing a lock is encryption, while the digital equivalent to opening a lock is decryption. Hence, when talking about protecting data by using cryptography, we use the terms encryption and decryption for protecting data and unprotecting data, respectively. Encrypted data are called cypher text. Cypher text looks like a useless pile of letters and figures to everyone who does not know how to decrypt it. However, cypher text is indeed useful but only for those who possess the key necessary to decrypt it. Decrypted cypher text is identical to the original data that have been encrypted. Hence, the whole round trip through cryptography can be summed up as: start with some data, produce cypher text by encrypting the original data with a cryptographic key, preserve the cypher text or send it to someone, and finally recover the original data by decrypting the cypher text with a cryptographic key. Figure 12-1 illustrates the basic functioning of cryptography.
1Nakamoto, Satoshi. Bitcoin: A peer-to-peer electronic cash system. 2008. https://bitcoin.
2See Van Tilborg, Henk, and Sushil Jajodia, eds. Encyclopedia of cryptography and security. New York: Springer Science & Business Media, 2014.

96
Step 12 | Identifying and Protecting User Accounts
Figure 12-1. Schematic illustration of basic cryptographic concepts and their terminology What happens if someone tries to decrypt cypher text by using an incorrect key? The result is a useless pile of numbers, letters, and signs that do not reveal any of the data that were encrypted.
Symmetric Cryptography
For many years people utilized methods of cryptography where the identical key was used to do both the encrypting and decrypting of data. Hence, everyone who was able to encrypt data with such a key was automatically able to decrypt cypher text created with that key as well. Since the identical key was used for both methods, this was called symmetric cryptography. Figure 12-2
illustrates the basic functioning of symmetric cryptography where the identical key is used to encrypt and to decrypt a short greeting.
Figure 12-2. Schematic illustration of symmetric cryptography However, it turned out that having one key for encryption and decryption was not always desirable. As a result, asymmetric cryptography was invented.
Asymmetric Cryptography
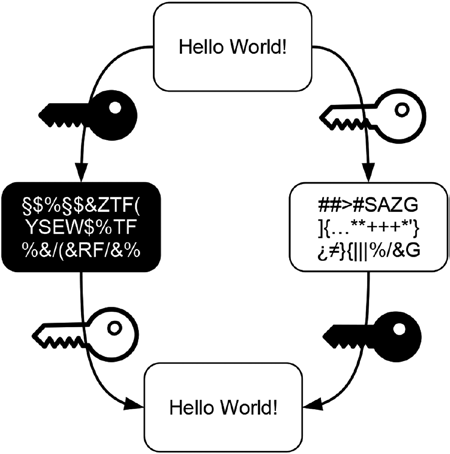
Asymmetric cryptography always uses two complementary keys. But there is a trick to this: cypher text created with one of these keys can only be decrypted with the other key and vice versa.
Figure 12-3 illustrates the encryption-decryption round trip for asymmetric cryptography. You can view this figure in the following way: The upper part of Figure 12-3 illustrates encryption, while the lower part illustrates decryption.
Blockchain Basics
97
There are two keys: a white key and a black key. Together they form the pair of corresponding keys. The original message is encrypted with the black key, which yields cypher text represented by the black box containing white letters. The original message can also be encrypted with the second key, which yields different cypher text represented by the white box containing black letters. For didactical reasons, the colors of the boxes representing cypher text and the colors of the keys used to produce them are identical in order to highlight their relation: The black key yields black cypher text, while the white key produces white cypher text.
Figure 12-3. Schematic illustration of asymmetric cryptography The lower part of Figure 12-3 illustrates how decryption works in asymmetric cryptography. Black cypher text can only be decrypted with the white key and vice versa.
The trick to asymmetric cryptography is that you can never decrypt cypher text with the key that was used to create it. The decision on which key to use for encryption and which to use for decryption is up to you. You can switch the roles of the keys as you like for every new piece of data you want to encrypt, but you always have to keep both keys for doing both encryption and decryption. If you have only one of the keys, your power is limited. While you can always create cypher text by applying your key to data, you cannot decrypt it because you are missing the complementary key. However, you can decrypt cypher text that was created with the corresponding complementary key. An isolated key is like a one-way street: You can drive down the street
Step 12 | Identifying and Protecting User Accounts
but you can never drive back on the identical street. Due to the asymmetric distribution of their cryptographic power, the two keys allow you to separate the group of people who are able to create cypher text from those who can decrypt it.
Asymmetric Cryptography in the Real World
Using asymmetric cryptography in real life consists of two major steps:
• Creating and distributing the keys
• Using the keys
Creating and Distributing the Keys
When using asymmetric cryptography in real life, you would give the two keys specific names in order to highlight each one’s role. Typically these keys are called the private key and public key. For that reason, asymmetric cryptography is called public-private-key cryptography. However, there are no such things as the private key and public key in asymmetric cryptography per se because you know that you can encrypt data and decrypt cypher text with each of them. It is the role that is assigned to these keys that makes them private or public. The public key is given to everyone, regardless of their trustworthiness.
Literally anyone can have a copy of the public key. However, the private key is kept safe and private.
Hence, the first steps to be performed in any application of asymmetric cryptography are:
1. Create a pair of complementary keys by using crypto-
graphic software
2. Give one key the name public key
3. Give the other key the name private key
4. Keep the private key for yourself
5. Give your public key to everyone else
Using the Keys
There are two general ways to use the pair of keys, which differ in the direction to which the data flows:
• Public to private
• Private to public
99
Public to Private
By using the keys in this way, the information flows from the public key, where it is encrypted, to the private key, where it is decrypted. This usage of the two complementary keys is similar to a mailbox, where everyone can put letters in but only the owner can open it. It is the straightforward usage of asymmetric cryptography because it fits our intuition about privacy and publicity in the same way as our address and our mailbox is public but its content is private.
Hence, this way of using asymmetric cryptography is all about sending information in a secured fashion to the owner of the private key. It works because everyone can create cypher text with the public key, but only the owner of the private key can decrypt the cypher text and read the message.
Private to Public
By using the keys in this way, the information flows from the private key, where it is encrypted, to the public key, where it is decrypted. This way of using the two keys is similar to a public news board or public notice board where everyone who has a copy of the public key can read messages but only the owner of the private key can create messages. Hence, this way of using asymmetric cryptography is all about proving authorship. It works because everyone can use the public key to decrypt cypher text that was created with the corresponding private key. The fact that cypher text created with the private key can only be decrypted with the corresponding public key serves as proof that the owner of the corresponding private key has encrypted the message.
Asymmetric Cryptography in the Blockchain
The blockchain uses asymmetric cryptography in order to achieve two goals:
• Identifying accounts
• Authorizing transactions
Identifying Accounts
The blockchain needs to identify users or user accounts, respectively, in order to maintain the mapping between owner and property. The blockchain uses the public-to-private approach of asymmetric cryptography for identifying user accounts and transferring ownership between them. Account numbers in the blockchain are actually public cryptographic keys. Hence, transaction data use the public cryptographic keys for identifying the accounts involved in the transfer of ownership. In this regard, the blockchain treats user accounts similar to mailboxes: They have a publicly known address and everyone is able to send messages to them.
Step 12 | Identifying and Protecting User Accounts
Authorizing Transactions
Transaction data always have to include a piece of data that serves as proof that the owner of the account who hands off ownership indeed agrees with the described transfer of ownership. The flow of information implied by this agreement starts at the owner of the account who hands off ownership and is supposed to reach everyone who inspects the transaction data. This kind of information flow is similar to that implied by the private-to-public use case of asymmetric cryptography. The owner of the account who hands off ownership creates some cypher text with his or her private key. All others can verify this proof of agreement by using the public cryptographic key, which happens to be the number of the account that hands off ownership. The details of this procedure, which is called digital signature, will be explained in more detail in the next step.
Outlook
This step explained the concept of asymmetric cryptography and how it is used as public-private-key cryptography in real life. Furthermore, this step explained that cryptographic public keys are used in the blockchain to identify user accounts. Furthermore, the lawful owner authorizes transactions by creating a digital signature that can be traced back to his or her private cryptographic key. The next step explains this concept in more detail, as this usage of asymmetric cryptography is less intuitive than the identification of accounts by public keys.
Summary
• The major goal of cryptography is to protect data from
being accessed by unauthorized people.
• The major cryptographic activities are:
• Encryption: Protecting data by turning them into cypher
text by utilizing a cryptographic key
• Decryption: Turning cypher text back into useful data
by utilizing a matching cryptographic key
• Asymmetric cryptography always uses two complemen-
tary keys: cypher text created with one of these keys can
only be decrypted with the other key and vice versa.
101
• When utilizing asymmetric cryptography in real life, these
keys are typically called the public key and private key in
order to highlight their role. The public key is shared with
everyone, while the private key is kept secret. For this
reason, asymmetric cryptography is also called public-
private-key cryptography.
• There are two classical use cases of public and private
keys:
• Everyone uses the public key to encrypt data that can
only be decrypted by the owner of the corresponding
private key. This is the digital equivalent to a public
mailbox where everyone can put letters in but only
the owner can open it.
• The owner of the private key uses it to encrypt data
that can be decrypted by everyone who possesses the
corresponding public key. This is the digital equivalent
to a public notice board that proves authorship.
• The blockchain uses asymmetric cryptography in order
to achieve two goals:
• Identifying accounts: User accounts are public
cryptographic keys.
• Authorizing transactions: The owner of the account
who hands off ownership creates a piece of cypher
text with the corresponding private key. This piece of
cypher text can be verified by using the corresponding
public key, which happens to be the number of the
account that hands off ownership.
13
Authorizing
Transactions
Utilizing the digital equivalent to
handwritten signatures
Step 12 provided a gentle introduction to asymmetric cryptography. It also pointed out that the blockchain uses public cryptographic keys as account numbers and utilizes the public-to-private approach of asymmetric cryptography for transferring ownership among accounts. However, that was only half of the story. The blockchain needs to ensure that only the lawful owner can transfer his or her property to other accounts. This is the point were the concept of authorization enters the scene. Hence, this step explains how asymmetric cryptography is used within the blockchain for authorizing transactions. In particular, this step is devoted to the concept of digital signatures, which utilize the private-to-public approach of asymmetric cryptography.
The Metaphor
Handwritten signatures serve an important purpose: they state agreement with the content of a document and agree with its execution. The reason why we accept handwritten signatures as evidence for agreement is the uniqueness of each person’s handwriting. Every human being has his or her own characteristic
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_13
Step 13 | Authorizing Transactions
way of writing his or her name. Hence, when we identify a name being written in a specific way, we conclude that the person who writes his or her name in that particular way has indeed produced that handwritten signature, and, as a result, we can conclude that this person has agreed with the content of the document and its implementation. This step explains the concept of stating agreement with transactions in an electronic ledger that is similar to handwritten signatures. This concept is crucial for the security of individual transactions in the blockchain.
The Goal
It is important to ensure that only the owner of an account can transfer the property associated with it to other accounts. Every attempt to access an account and its associated property by any person other than the lawful owner should be identified as unauthorized and should be rejected.
The Challenge
The peer-to-peer system under consideration is open to everyone. Hence, everyone may create transactions and can submit them to the system.
Transaction data are the foundation of describing and clarifying ownership.
Only the lawful owner of an account should be able to transfer property or ownership rights associated with his or her account to another account. The challenge of the blockchain is to maintain its openness while restricting the transfer of ownership to the lawful owner.
The Idea
The main idea of ensuring that only the lawful owner can transfer ownership is to utilize a digital security measure that is equivalent to handwritten signatures and serves the same purpose: identifying an account, stating the agreement of its owner with the content of specific transaction data, and approving its execution by allowing the data to be added to the history of transaction data.
A Short Detour to Digital Signatures
Digital signatures are the equivalent of handwritten signatures. They utilize cryptographic hashing and the private-to-public information flow of asymmetric cryptography. The following short example illustrates the three major elements of digital signatures:
• Creating a signature
• Verifying data by using the signature
• Identifying fraud by using the signature
Blockchain Basics
105
Creating a Signature
Let’s say I want to send a Hello World! greeting to the world in an authorized way. Hence, I create a message that contains the greeting and a corresponding digital signature. Figure 13-1 depicts the whole process of signing data digitally.
The process starts with the white box in the top left area of Figure 13-1 that
contains the greeting. I create the hash value of the greeting, which is 7F83B165, and encrypt it with my private key. The cypher text of the greeting’s hash value (the black box containing white letters) is my digital signature of the greeting.
It is unique with respect to two aspects: First, it can be traced back to me uniquely because I created it with my unique private key. Second, it is unique regarding the text of the greeting because it is based on the digital fingerprint of the greeting. Both the greeting and the digital signature are put together in a file (the gray box), which is my digitally signed message to the world.
Figure 13-1. Schematic illustration of creating a digital signature Verifying Data by Using the Signature
The message, that is, my greeting together with the digital signature, is sent to the whole world. Everyone can verify that I authorized this message by utilizing my public key. Figure 13-2 illustrates the process of verifying the message by using the digital signature. The process starts with the greeting. At first the recipient of the message calculates the hash value of the greeting by himself, which yields the value 7F83B165. Then the recipient of my message decrypts the attached cypher text (the digital signature) with my public key.
Doing so yields the value 7F83B165, which is the hash value of that version of the greeting I wanted to send to the world. Comparing both hash values
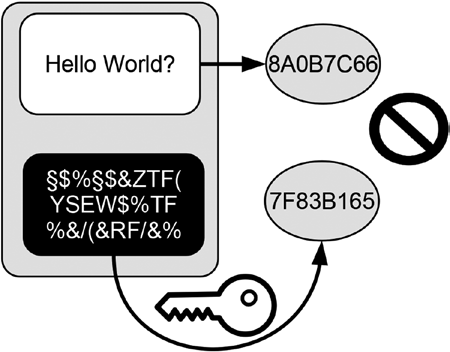
106
Step 13 | Authorizing Transactions
completes the verification. Since both hash values are identical, the recipient correctly concludes, first, that the message was signed by me, because he was able to decrypt the signature with my public key, and second, that the greeting text found in the message is indeed the one I wanted to send because the decrypted cypher text is identical with the hash value of the greeting in the message.
Figure 13-2. Using a digital signature to verify a message Identifying Fraud by Using the Signature
Figure 13-3 illustrates how the digital signature points out a forged greeting.
Figure 13-3. Using a digital signature to identify fraud
107
Figure 13-3 shows the message that arrived in my friend’s mailbox. Note the change of the greeting text. Some hacker replaced the exclamation mark with a question mark and hence changed the whole tone of the greeting. This is not the way I wanted to greet the world. Fortunately, the digital signature will point out to everyone that the message has been altered against my will.
At first the recipient of the message will create the hash value of the greeting by himself, which yields the value 8A0B7C66. Then the recipient of my message decrypts the digital signature with my public key. Doing so yields 7F83B165, which is the hash value of the version of the greeting I wanted to send to the world. Comparing both hash values reveals that they are not identical. This clearly points out that the greeting in the message is not the greeting I wanted to send to the world. Hence, everyone concludes that I did not authorize this message, and, therefore, no one will make me responsible for its content.
How It Works
Digital signatures in the blockchain fulfill the following requirements:
• They state agreement of the owner of the account who
hands off ownership with specific transaction data.
• They are unique for the whole content of transaction
data in order to prevent it from being used to authorize
other transactions without the agreement of its author.
• Only the owner of the account who hands off ownership
can create such a signature.
• They are easy to verify by everyone.
There are two use cases of digital signatures in the blockchain:
• Signing a transaction
• Verifying a transaction
Signing a Transaction
In order to create a digital signature for a transaction, the owner of the account who hands off ownership performs the following steps:
1. Describes the transaction with all necessary informa-
tion such as the involved account numbers, amount being
transferred, and so on except the signature itself as it is
not yet available.
2. Create the cryptographic hash value of the transaction
data.
Step 13 | Authorizing Transactions
3. Encrypt the hash value of the transaction with the private key of the account that hands off ownership.
4. Add the cypher text created in point 3 to the transaction
as its digital signature.
Verifying a Transaction
In order to verify a transaction, the following steps must be performed: 1. Create the hash value of the transaction data to be verified except the signature itself.
2. Decrypt the digital signature of the transaction under
consideration with the account number that hands off
ownership.
3. Compare the hash value of step 1 with the value gained in step 2. If both are identical, the transaction is authorized by the owner of the private key that corresponds to the
account that hands off ownership, otherwise it is not.
Why It Works
Digital signatures of transaction data are a combination of the following:
• Cryptographic hash values of transaction data
• Cypher text that can be traced back to the correspond-
ing private key of an account
Due to the fact that cryptographic hash values can be considered digital fingerprints, they are unique for each transaction. A constituting property of public-private-key cryptography is that cypher text created with one key can only be decrypted with the corresponding key. The association of both keys is unique. Hence, a successful decryption of cypher text with a specific public key serves as proof that it was created with the corresponding private key.
Both concepts combined are used to create cypher text that can be traced back uniquely to one specific transaction data and to one specific private key in one process. This property make digital signatures suitable to serve as proof that the owner of the private key that was used to create the digital signature indeed agrees with the content of the transaction.
109
Outlook
This step completes the process of how the blockchain protects ownership on the level of individual transaction data. As a result, transactions and their purpose to transfer and prove ownership are safe and secure. However, it is important to ensure that transaction data are not only secured on the individual level. There is still a need to store the whole history of transaction data in a secure way. The next steps will explain in more detail how to achieve this.
Summary
• Handwritten signatures on documents state the agree-
ment of their authors with the content of the signed
documents and authorize their implementation.
• The evidential power of handwritten signatures is based
on the uniqueness of the handwriting.
• Digital signatures are the digital equivalent to handwrit-
ten signatures.
• Digital signatures serve two purposes:
• Identify its author uniquely
• State agreement of its author with the content of a
document and authorize its execution
• In the blockchain, digital signatures of transactions are
cryptographic hash values of transaction data encrypted
with the private key that corresponds to the account that
hands off ownership.
• Digital signatures in the blockchain can be trace back
uniquely to one specific private key and to one specific
transaction in one process.
14
Storing
Transaction
Data
Building and maintaining a history of
transaction data
Based on the previous five steps, you should now be able to trace ownership based on the whole history of transaction data and to describe individual transfers of ownership in a secure way by authorizing transactions with digital signatures and identifying user accounts uniquely. However, I have not spent any time discussing how to store all the transaction data that make up the transaction history in a secure fashion. This is the point where the blockchain-data-structure enters the discussion. This step introduces the blockchain-data-structure and explains how it is constructed.
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_14
Step 14 | Storing Transaction Data
The Metaphor
Do you remember the last time you visited a library and used one of the traditional card catalogs? Library catalogs are registers of all of the books owned by a library. Some traditional libraries still use card catalogs for managing their inventory. Each card in one of these catalogs represents one book, and the card displays the major information about that book, such as the name of the author, the title of the book, the date of publication, and the location of the book within the library such as floor, room, shelf, and rack number. In order to identify books, the catalog cards often contain unique reference numbers that are also displayed on the books’ spines. Most libraries maintain more than one card catalog, which differ with respect to the criterion used to order the cards. For example, in an author catalog, the cards are sorted alphabetically according to the names of authors, while in a title catalog the cards are sorted alphabetically according to the titles. One could also come up with an ordering catalog whose cards are sorted according the order in which the books where added to the library. This step explains how the blockchain stores transaction data in a way that is similar to a library with an ordering catalog.
The Goal
The goal of the blockchain is to maintain the whole history of transaction data in an ordered fashion.
The Challenge
The challenge is to store all transaction data that have ever happened in a way that preserves the order in which the transactions happened and in a way that quickly and easily detects any changes made to the data. Detecting changes quickly is important since it is the basis to prevent manipulation or forgery of the transaction history.
The Idea
The idea is to create a library of transaction data and to maintain an ordering catalog, which preserves the order in which transactions were added to the library. In order to detect any changes made either to the ordering catalog or to the individual transaction data, the data must be stored in a change-sensitive manner by using hash references.
113
Transforming a Book into a Blockchain-Data-
Structure
This section explains how to turn a book into a small library with an ordering catalog, which turns out to be a simplified version of the blockchain-data-structure.
Starting Point: A Book
For many centuries, written information was preserved on unwieldy spools of parchment, which were called scrolls. Nowadays, we are used to having written information preserved in codices: hardback-bound bundles of numbered pages, which we call books. Because books are so commonplace, we may take their innovation for granted. Some of their important properties include:
• Storing content: Books store content on their pages.
• Ordering: The sentences on the pages as well as the pages
within the book are kept in order.
• Connecting pages: Pages are physically connected via the
book spine and logically connected via their content and
the page numbers.
As a result of these properties, we can browse through books forward and backward by moving pages or we can jump directly to specific pages by utilizing the page numbers. Let’s see what we could achieve if we changed some of these properties.
Transformation 1: Making Page Dependency Explicit
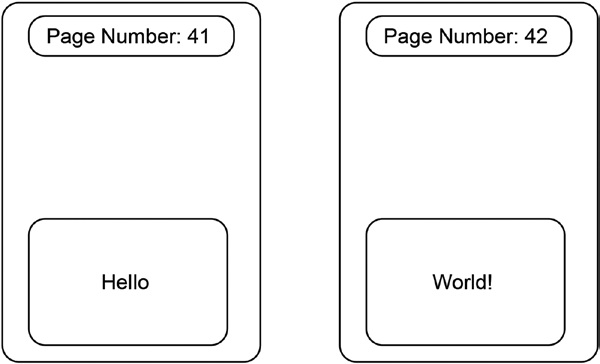
Figure 14-1 exhibits a schematic illustration of two pages from a very simple book. Each page contains a top margin that presents the page number and a content area that carries only one word.
114
Step 14 | Storing Transaction Data
Figure 14-1. A schematic illustration of book pages
The page numbers serve an important purpose: You can find out whether someone removed a page from the book by verifying that the page numbers continue without leaving out a number. Imagine you are currently reading page number 42 of our simplified book. What page number should the preceding page have? This is very simple: The preceding page should have the number 41, which equals 42 minus 1. In order to verify that indeed no one has removed the preceding page, we compare the number being displayed on the preceding page with the expected page number, which is the number of the current page minus 1. If both numbers are equal, we can conclude that the preceding page has not been removed.
Why do we know that the number of the preceding page should equal the current page’s number minus 1? The answer is that we assume that all books follow the convention of labeling the pages consecutively with natural numbers.
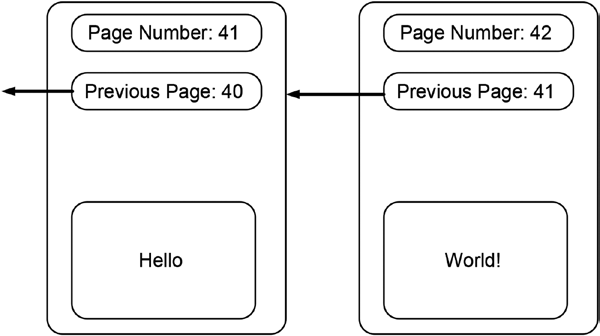
But what if that assumption is not true because the author or the publisher of the book decided to use a different page numbering schema (e.g., by only using even numbers or multiples of three)? In this case, our approach of verifying that the preceding page has not been removed fails. In order to make it easy to verify that no page has been removed from the book, we could point out the connection of each page to its predecessor explicitly. Figure 14-2 shows how this is done in our simple book. Each page not only exhibits its own number but also exhibits the number of its preceding page. This page numbering schema makes the dependency between any page and its preceding page explicit. The explicit referencing of the preceding page makes verifying that no page has been removed very easy since it does not rely on implicit assumptions anymore.
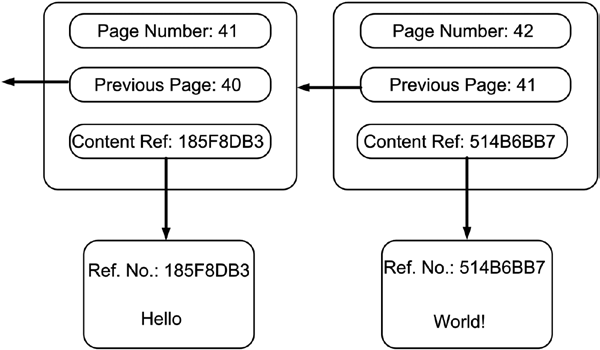
Blockchain Basics
115
Figure 14-2. Book pages with explicit reference to their preceding pages Transformation 2: Outsourcing the Content
The pages of our book contain the content and the information necessary to maintain their ordering: the page numbers. We can make our book handier by outsourcing the content and let it solely focus on the task of maintaining the order. Figure 14-3 shows how the pages of our schematic book look after we outsourced the content. The pages no longer contain any content, instead they contain reference numbers that point to the content, which can be stored wherever we want (e.g., in a box, on a shelf, or somewhere else).
Figure 14-3. Book pages with reference values to the outsourced content
116
Step 14 | Storing Transaction Data
The achievement of this step is the following: We turned our book into a small library. The book that once stored content and page numbers together has been turned into a catalog, whose sole purpose is maintaining the order of the content while the content is stored on separated pages that are identified by unique reference numbers.
Transformation 3: Replacing Page Numbers
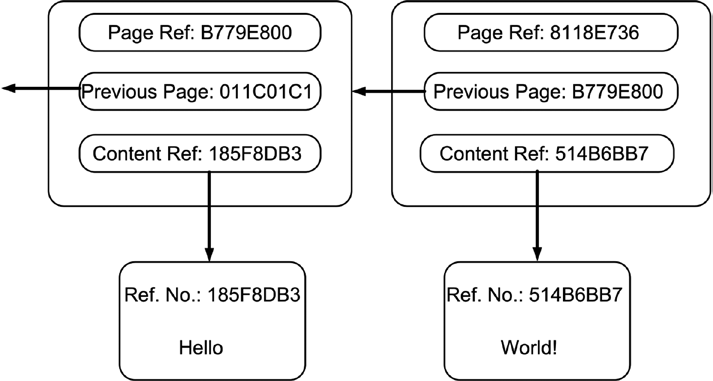
Our book that is now an ordering catalog maintains the order of its pages in two distinct ways: First, by the physical location of the pages within the book fixated in the book spine; second, by the page numbers and the explicit referencing of the preceding page. Due to the fact that the physical construction of the book preserves the order of the pages, we can experiment with a different page numbering schema. We can actually replace the natural numbers used to label the pages with reference numbers. Figure 14-4 shows the result of this transformation. For example, the page previously carrying the page number 42 is now identified with the page reference number 8118E736. In a similar fashion, the page that previously carried the page number 41 is now identified with the page reference number B779E800. Notice that the references to the preceding page have been updated as well. The page with the reference number 8118E736 contains the correct reference number to its preceding page.
Figure 14-4. Book pages using reference numbers as page numbers
117
Transformation 4: Creating Reference Numbers
In the previous transformation, we replaced page numbers in our book with reference numbers. However, I have not discussed how they would be created.
The best way to create unique reference numbers is to use cryptographic hash values. Hence, we can identify pages in our catalog as well as the corresponding content pages with their cryptographic hash values, which are digital fingerprints of their content. For simplicity, both Figure 14-3 and Figure 14-4
use shortened hash values. (You can verify the results by using the tool pro-
vided at www.blockchain-basics.com/Hashing.html.) For example, the content page that contains the word Hello is identified by the shortened hash value of Hello that is 185F8DB3. The reference value of our book pages are calculated based on their content, which is the content reference number and the reference number of the preceding page. For example, the page reference number B779E800 is the hash value of 011C01C1 185F8DB3.
Transformation 5: Getting Rid of the Book Spine
Our ordering catalog is an unusual book because each of its pages contains its own reference number, the reference number of the preceding page, and the reference number of the corresponding content page. However, our ordering catalog is still a traditional book whose pages are fixated in the book spine.
What happens if we get rid of the book spine and turn our ordering book into a pile of loose pages? By doing so we destroy the physical connection of the pages and as a result we lose the physical ordering of our pages as well.
Fortunately, the ordering of the pages is not completely lost. Every page contains the reference number of its preceding page. As a result, we can move from page to page backward by following the page reference numbers to the preceding page. If we keep the last page of the ordering catalog separated, we can always browse through all pages in reverse order.
Goal Achieved: Appreciating the Result
Let’s summarize what we have achieved in this example. We turned a classical book into two physically unordered piles of loose pages that are linked together with unique reference numbers. One pile of pages contains the content, while the other pile of pages maintains the ordering. For simplicity, we refer to the latter pile of pages as an ordering catalog. Each page of the ordering catalog contains the reference number to its preceding page and the reference number of the corresponding content page. As a result, we have separated ordering from storing information and the logical location (the order) from the physical location of the pages. Due to the fact that we used hash values as reference numbers, everyone can verify their correctness
Step 14 | Storing Transaction Data
by simply recalculating them. Since the pages of the ordering catalog are no longer fixated on a book spine, we can only browse through it backward in a page-by-page fashion by following the page reference numbers that point to the preceding page. For easy reference, Table 14-1 summarizes the properties of our book before and after the transformations.
Table 14-1. Comparing the Book Before and After the Transformation Property
Book
Transformed Book
Storing content
On the pages themselves
On separate content pages
Each content page is identified
by a unique reference number
Ordering content
Physically: Based on the location
Logically: Via an ordering catalog
of the pages within the book
that contains reference values
Logically: Based on the page
to the content pages
numbers
Connecting pages
Physically: By fixating pages in the
Logically: Via reference numbers
book spine
Logically: Based on page numbers
Browsing through
Forward
Backward only: By following
the pages
Backward
the reference numbers to the
preceding page
Jumping to pages directly by using
page numbers
The Blockchain-Data-Structure
What is the blockchain-data-structure? Actually, you already know the answer because the preceding example developed a simplified blockchain-data-structure. However, we used different terminology. This section finishes the analogy by linking the elements of the transformed book with the terminology used in the context of the blockchain.
Our transformed book consists of:
• A mental unit consisting of a page of the ordering catalog
and its corresponding content page
• A pile of loose pages called the ordering catalog
• A pile of loose pages that contain the content
• Page reference numbers for identifying and linking pages
of the ordering catalog
• Content reference numbers for identifying and linking
content pages
119
For easy reference Table 14-2 at the end of this section summarizes the results by comparing the elements of our simplified book after transformation with elements of the blockchain-data-structure.
Table 14-2. Comparing the Transformed Book with the Blockchain-Data-Structure Transformed Book
A page in the ordering catalog
A block header
The whole ordering catalog
The chain of block headers
The reference number of a page in the
The cryptographic hash value of a block
ordering catalog
header
The reference number to the preceding page
The cryptographic hash value of the
preceding block header
Content
Transaction data
A content page
A Merkle tree containing transaction data
Reference to the content page
The root of the Merkle tree that contains
transaction data
The mental unit of a page of the ordering
One block of the blockchain-data-structure
catalog and its corresponding content page
The whole ordering catalog and all content
The blockchain-data-structure
pages together
The Mental Unit of a Page of the Ordering Catalog
and Its Corresponding Content Page
The mental unit of a page of the ordering catalog and its corresponding content page relates to one block in the blockchain-data-structure. All these blocks together form the blockchain-data-structure. It is important to point out that the unit of ordering page and corresponding content page is only a mental unit because the pages of the ordering catalog and the content pages are physically distinct entities. The former refer to the latter via hash references, which as a result constitutes the mental unity.
Ordering Catalog
The ordering catalog of our transformed book equates to the chain of block headers in the blockchain-data-structure. Each page of the ordering catalog equates to a single block header in the blockchain-data-structure. Since the 1Nakamoto, Satoshi. Bitcoin: A peer-to-peer electronic cash system. 2008. https://
Step 14 | Storing Transaction Data
block headers are connected with one another via references in a linear fashion, like the links of a chain, they form a chain of block headers. Similar to our ordering catalog, the chain of block headers does not store transaction data directly, but only stores hash references to the corresponding transaction data. This is the point where the mental unit of the ordering catalog and content becomes important.
Content Pages
The content of the transformed book is equivalent to the transaction data being maintained by the blockchain. They are specific to our application area that is managing ownership. There are no content pages in real-world blockchain applications; I made up the term content pages for didactical reasons.
Real-world blockchain applications store the content data (e.g., transaction data) directly in a database, and we refer to them as Merkle trees, whose roots are stored in block headers.
Catalog Page Reference Numbers
The page reference numbers of our transformed book used to identify pages of the ordering catalog equate to cryptographic hash values of individual block headers in the blockchain-data-structure. They are called block hash or previous block’s hash, respectively. They are used to identify each block header uniquely and to refer to the previous block header. The actual referencing from one block header to its predecessor is done by hash reference.
Content Reference Numbers
The content reference numbers in our transformed book used to identify content pages equate to hash references in the chain of block headers that point to the associated transaction data. To be more specific, the content reference number that is stored in a block header is the root of a Merkle tree of the transaction data being stored in a database. This is the point where the mental unit of the ordering catalog (block header) and its corresponding content (Merkle tree with transaction data) are constituted.
Storing Transactions in the Blockchain-Data-
Structure
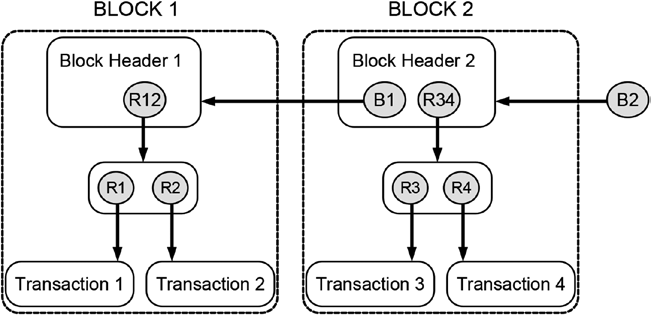
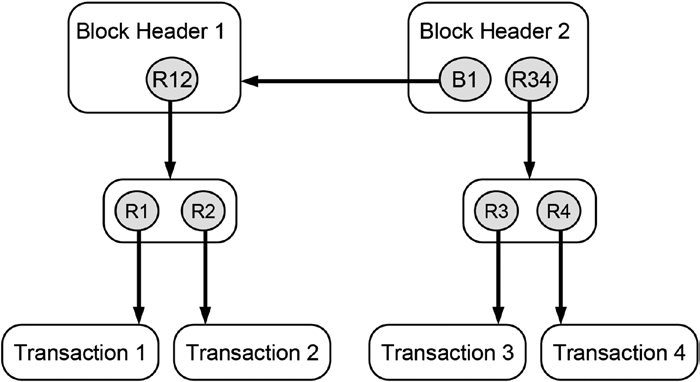
Figure 14-5 summarizes what you have learned by schematically depicting a blockchain-data-structure that stores four transactions. The illustration given in Figure 14-5 shows a simplified blockchain-data-structure that consists of
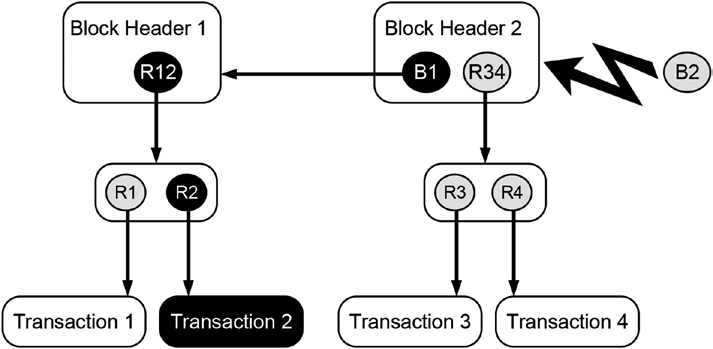
Blockchain Basics
121
two blocks labeled BLOCK 1 and BLOCK 2. In order to emphasize the mental nature of the blocks, they are drawn with dashed lines. Both blocks contain block headers labeled Block Header 1 and Block Header 2, respectively.
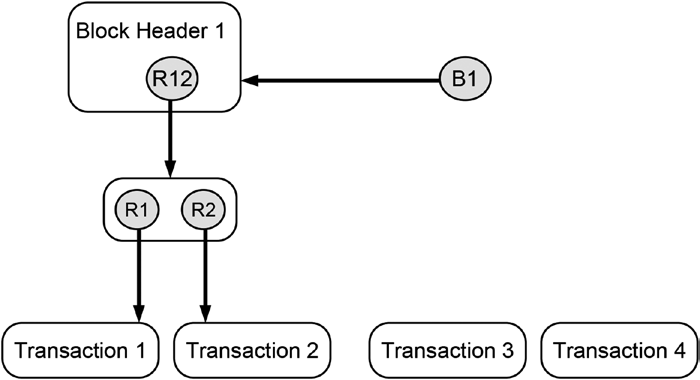
BLOCK 1 is the very first block in this data structure, hence, it does not have a preceding block, and, consequently, Block Header 1 does not contain any reference to a preceding block header. Since BLOCK 2 has a predecessor, Block Header 2 maintains a hash reference to its preceding block header labeled as B1. The depicted blockchain-data-structure maintains hash reference to two distinct Merkle trees whose roots are labeled R12 and R34, respectively. The labels of the Merkle roots already give us an indication of the transaction data they contain (e.g., the Merkle tree with the root R12 contains the first two transactions labeled as Transaction 1 and Transaction 2 and their corresponding hash references R1 and R2 that point to them).
If you joined a distributed peer-to-peer system that maintained a blockchain-data-structure, as shown in Figure 14-5, you would receive all transaction data, all hash reference values, and all block headers. Based on these data, your local computer would create the blockchain-data-structure including the hash references that point to data stored on your local computer. Equipped with these data and the reference to the most current block header, you could browse through the history of all transaction data that were ever submitted to the system since its creation in reverse order, which in our case is just four transactions. Note that the reference to the most currently added block header is called the head of the blockchain-data-structure because it is the place where the next block will be added. Sometimes both the most currently added block header and the reference that points to it is called the head of the blockchain-data-structure. In Figure 14-5 the reference labeled B2 is the head of the blockchain-data-structure. It is important not to mix the terms “head” and “header”: The blockchain-data-structure consists of many blocks that each has its own header, but the whole blockchain-data-structure has only one head.
Figure 14-5. A simplified blockchain-data-structure containing four transactions
Step 14 | Storing Transaction Data
■ Caution The blockchain-data-structure discussed in this step and illustrated in Figure 14-5
has been simplified for didactical reasons. Many details regarding the information stored in the block headers have been left out deliberately. Some of them will be covered in the next steps as you complete your understanding of the blockchain.
Outlook
This step introduced the blockchain-data-structure and explained its construction. The way in which the blockchain-data-structure makes extensive use of hash references makes it a very change-sensitive data store. The next step explains that property in more detail, as it is the key to understanding how the blockchain is made secure.
Summary
• The blockchain-data-structure is a specific kind of data
structure that is made up of ordered units called blocks.
• Each block of the blockchain-data-structure consists of a
block header and a Merkle tree that contains transaction
data.
• The blockchain-data-structure consists of two major data
structures: an ordered chain of block headers and Merkle
trees.
• One can imagine the ordered chain of block headers as being the digital equivalent to an old-fashioned library card catalog, where the individual catalog cards are sorted according to
the order in which they were added to the catalog.
• Having each block header referencing its preced-
ing block header preserves the order of the individual
block headers and blocks, respectively, that make up the
blockchain-data-structure.
• Each block header in the blockchain-data-structure is
identified by its cryptographic hash value and contains a
hash reference to its preceding block header and a hash
reference to the application-specific data whose order it
maintains.
• The hash reference to the application-specific data is
typically the root of a Merkle tree that maintains hash
references to the application-specific data.
15
Using the Data
Store
Chaining blocks of data
Step 14 introduced the blockchain-data-structure. It turns out that the blockchain-data-structure consists of two major components: an ordered chain of block headers and Merkle trees containing transaction data. This data structure was invented with the goal of storing transaction data in a secure fashion. But what does storing data in a secure fashion mean in this context? Answering this question is the purpose of this step. This step points out the consequences of changing data in the blockchain and it illustrates how the blockchain-data-structure detects changes. Furthermore, this step highlights the power of hash references when storing data in a change-sensitive manner. Finally, this step explains how to add new blocks to the blockchain-data-structure in a correct way.
The Metaphor
Knitting is the craft of turning yarn into a textile or fabric by creating a sequence of multiple interlocking loops of yarn, the so-called stitches. When produced manually, the sizes of knitting stitches vary significantly. Hence, during the process of knitting, it is sometimes necessary to correct individual stitches.
In order to correct a knitting stitch located somewhere in the fabric, one has
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_15
Step 15 | Using the Data Store
to rip out all of its succeeding stitches in reverse order starting from the end of the row until one eventually arrives at the stitch to be corrected. After the stitch under consideration has been corrected, one has to re-create all its succeeding stitches. Since this procedure is quite elaborate, it is important to ensure that all stitches fulfill the quality requirements when they are created the first time. This step explains that using the blockchain-data-structure is very similar to knitting: Adding a new block at the end of the blockchain-data-structure is easy, while changing data located somewhere in the chain is quite elaborate. With this metaphor in mind, you should easily be able to understand how the blockchain-data-structure detects changes, on the one hand, and how data are added and changed correctly, on the other hand.
Adding New Transactions
In order to understand how to add new transactions to an existing blockchain-data-structure in an orderly way, let’s consider a simple example.
Figure 15-1 illustrates the initial situation of a blockchain-data-structure that consist of one block only. The existing blockchain-data-structure only maintains two transactions. Transaction 3 and Transaction 4 at the bottom of Figure 15-1 are not yet added to the blockchain-data-structure. The steps to be performed in order to add new transaction data are:
1. Create a new Merkle tree that contains all new transac-
tion data to be added, as shown in Figure 15-2.
2. Create a new block header (Block Header 2) that con-
tains both the hash reference (B1) that points to the
header of its preceeding block (Block Header 1) and the
root of the Merkle tree that contains the new transaction
data (R34), as shown in Figure 15-3.
3. Create a new hash reference (B2) to the new block
header, as shown in Figure 15-4, and declare it the the new head of the updated blockchain-data-structure.
Remember that the reference that points to the most
currently added piece of data in a chain is also called the
head of the whole chain (see Step 11).
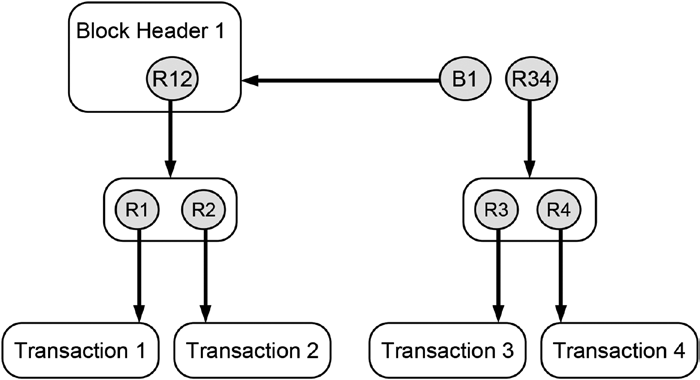
Blockchain Basics
125
Figure 15-1. Initial situation: Two new transactions (Transaction 3 and Transaction 4) should be added to the existing blockchain-data-structure
Figure 15-2. Step 1: Creating a new Merkle tree that contains the new transactions
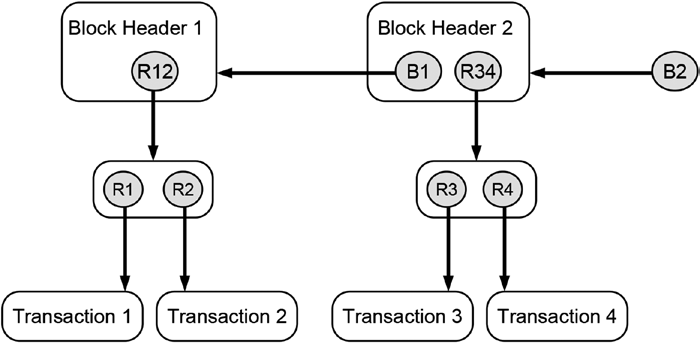
126
Step 15 | Using the Data Store
Figure 15-3. Step 2: Create a new block header that contains both the hash reference to its preceding header and the root of the Merkle tree that contains the new transaction data Figure 15-4. Step 3: Create a new hash reference that points to the new block header, which is now the new head of the whole updated blockchain-data-structure
Blockchain Basics
127
Detecting Changes
The step depicted in Figure 15-4 serves as the initial situation for studying the impact of changing data that are already part of the blockchain-data-structure.
I will discuss the following cases:
• Changing the content of transaction data
• Changing a reference in the Merkle tree
• Replacing a transaction
• Changing the Merkle root
• Changing a block header reference
Changing the Content of Transaction Data
Figure 15-5 illustrates what happens if we change Transaction 2. This transaction is part of a Merkle tree, which consists of hash references. By changing some properties of the Transaction 2 (e.g., the amount of goods being transferred or the account that receives ownership), one also changes its fingerprint or its cryptographic hash value, respectively. As a result, the hash reference R2 that pointed to the original transaction data is broken. It detects that the transaction data it originally referred were changed in the meantime and hence violates the rules of staying unchanged. As a result, the whole blockchain-data-structure is invalid.
Figure 15-5. Changing the details of a transaction invalidates the hash reference that pointed to the original data, which invalidates the whole data structure
128
Step 15 | Using the Data Store
Changing a Reference in the Merkle Tree
Figure 15-6 illustrates what happens if one not only changes details of a transaction but also changes the hash reference that points to the updated transaction. The updated hash reference (R2) is valid as it correctly points to the new transaction data. However, the updated hash reference is part of a Merkle tree whose root is a hash reference as well. The root of the Merkle tree (R12) points to a piece of data that contains the hash references R1 and R2. The latter one has been changed in order to be consistent with the manipulated version of Transaction 2. Hence, the cryptographic hash value of the piece of data containing the updated version of R2 changes as well, which in turn invalidates the root of the Merkle tree R12.
Figure 15-6. Changing a transaction and its hash reference in the Merkle tree invalidates the root of the Merkle tree, which invalidates the whole data structure Replacing a Transaction
Figure 15-7 considers the case of replacing a whole transaction instead of only manipulating details of an existing transaction and updating its hash reference.
Blockchain Basics
129
Figure 15-7. Replacing a transaction and its hash reference in the Merkle tree invalidates the root of the Merkle tree, which invalidates the whole data structure When you compare Figure 15-6 with Figure 15-7, you can only find minor difference regarding the name of the transaction and its hash reference.
Concerning the consequences, both illustrations are identical. In both cases the root of the Merkle tree R12 will be invalid due to changes that happened within the Merkle tree. As a result, we find that changing a transaction or replacing a transaction will have the same impact on the blockchain-data-structure. The manipulation will be detected in both cases and will invalidate the whole data structure.
■ Note Changing or replacing data in the blockchain-data-structure will have identical results as both have identical effects on hash references.
Changing the Merkle Root
Figure 15-8 illustrates what happens if a whole Merkle tree, including its root, is changed.
130
Step 15 | Using the Data Store
Figure 15-8. Changing a Merkle tree invalidates the hash reference that points to the block header that contains it, which in turn invalidates the whole data structure The root of the manipulated Merkle tree (R12) is part of a block header (Block Header 1). The change of the Merkle root changes the cryptographic hash value of Block Header 1, which in turn causes the hash reference that points to it (B1) to be invalid. The hash reference B1 that maintains the connection or serves as a link from Block Header 2 to Block Header 1 becomes invalid as it detects the change. As a result, the whole blockchain-data-structure becomes invalid.
Changing a Block Header Reference
Figure 15-9 illustrates what happens if not only a whole Merkle tree but also the hash reference to the manipulated block header is changed.
Blockchain Basics
131
Figure 15-9. Changing a hash reference within a block header invalidates the hash reference that points to the manipulated block header, which in turn invalidates the whole data structure
If the hash reference (B1) to the manipulated block header (Block Header 1) is changed, the following happens: Starting with hash reference B1, all hash references that point toward the manipulated data are consistent and valid since they were adjusted to the performed manipulation. However, the manipulated hash reference B1 is part of Block Header 2 and hence its cryptographic hash value changes, which in turn invalidates the hash reference B2 that pointed to the original data block header containing the original version of the hash reference B1. As a result, the whole blockchain-data-structure is invalid as well.
Changing Data Orderly
After this discussion of the many approaches to manipulate the blockchain-data-structure, which all yielded an invalid data structure, it is time to illustrate what needs to be done to change or update the blockchain-data-structure orderly.
Figure 15-10 illustrates how to change the blockchain-data-structure in the correct way.
132
Step 15 | Using the Data Store
Figure 15-10. Changing a transaction orderly includes changing all subsequent hash references
If we consider changing or updating some details of Transaction 2, we have to subsequently update the whole sequence of hash references: R2, R12, B1, and B2. This means that all hash references, starting with the one that directly points to the manipulated data and ending with the hash reference that points to the most recent block header as well as all hash references in between them, need to be changed and updated so that they reflect the changes of their targets. This is quite an elaborate task. And it is an elaborate process on purpose. All of this work is necessary to keep the whole blockchain-data-structure consistent and to keep its integrity. All other attempts to change or manipulate data that are part of the blockchain-data-structure will cause invalid hash references, which in turn will invalidate the whole data structure.
Intended vs. Unintended Changes
The preceding discussion showed that the blockchain-data-structure pursues a radical all-or-nothing approach when it comes to changing its data: One either changes the whole data structure completely from the point that causes the change until the head of the whole chain or one better leave it all unchanged in the first place. All other half-hearted, halfway through, or partial changes will leave the whole blockchain-data-structure in an inconsistent state, which will be detected easily and quickly. This is due to the properties of hash references, where the blockchain-data-structure does not differentiate between intended or unintended changes. Actually there are no such things as intended or unintended changes in the blockchain. These words refer to a valuation of the motives or the person who caused a change. But the blockchain-data-structure values neither the motives nor the person who causes an
133
inconsistency. The blockchain only cares about correctness and consistency of all its hash references. If one of them is invalid, the whole data structure is invalid, regardless of who or what caused that change or why it was made. And this property makes the blockchain-data-structure very valuable.
Outlook
This step illustrated in great detail how the blockchain-data-structure deals with changes of its data. It turned out that the blockchain-data-structure is very change sensitive. It pursues a radical all-or-nothing approach when it comes to changing its data. The next step explains how this property can be used to make data unchangeable, which makes the blockchain-data-structure the perfect candidate for storing data in an unreliable and untrustworthy environment.
Summary
• The steps to be performed in order to add new transac-
tion data to the blockchain-data-structure are:
• Create a new Merkle tree that contains all new
transaction data to be added.
• Create a new block header that contains both a hash
reference to its preceding header and the root of the
Merkle tree that contains the new transaction data.
• Create a hash reference to the new block header,
which is now the current head of the blockchain-
data-structure.
• Changing data in the blockchain-data-structure requires
renewing all hash references starting with the one that
directly points to the manipulated data and ending with
the head of the whole blockchain-data-structure as well
as all hash references in between them.
• The blockchain-data-structure pursues a radical all-or-
nothing approach when it comes to changing its data:
One either changes the whole data structure completely
starting from the point that causes the change until the
head of the whole chain or one better leave it unchanged
in the first place.
Step 15 | Using the Data Store
• All half-hearted, halfway through, or partial changes will
leave the whole blockchain-data-structure in an inconsis-
tent state, which will be detected easily and quickly.
• Changing the blockchain-data-structure completely is a
very elaborate process on purpose.
• The high sensitivity of the blockchain-data-structure
regarding changes is due to the properties of hash
references.
16
Protecting the
Data Store
Discovering the power of immutability
Step 15 concluded with the finding that the blockchain-data-structure stores data in a change-sensitive manner. Any alteration of data stored in the blockchain-data-structure will stand out and require an elaborate process for incorporating it into the existing structure. This step explains how that property can be used to prepare the history of transaction data to be shared and distributed in an untrustworthy environment without having to fear that dishonest members of a peer-to-peer system can manipulate its content for its own advantage.
The Metaphor
Let’s assume I want to pretend to be a member of a prestigious aristocratic family. How could I achieve that? Forging my family tree could do that. For example, I could make up an aristocratic grandfather and connect myself to him with a forged family tree. Will this suffice to convince others from my fake aristocratic roots? Well, this fake will be quickly uncovered since family trees rarely exist in isolation; instead, they are connected and interwoven with other family trees via family relationships. Hence, if none of the family trees
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_16
Step 16 | Protecting the Data Store
of the established aristocratic families have a reference or relation to my fictional grandfather, my fictional family history will be quickly discovered as fake.
In order to get my fictional family accepted, I would need to forge the family documents of some of the established aristocratic families by embedding references to my fictional family tree in their family history. But even this may not suffice. Real people have real lives and leave their footprints in our world. But my fictional grandfather never really lived. Hence, I have to make up his life in order to make the fake appear real. This implies that I have to invent the entire life of my fictional grandfather, including his childhood as well as his education and career history. Additionally, the supporting documents would also need to be faked, such as the birth certificate, school registration documents, school certificates, university degrees, professional certifications, memberships, and so on. Schools, universities, and employers maintain records of their students and employees and publish almanacs and photographs of social events. Hence, it would be necessary to manipulate their documents as well in order to make my fictional grandfather a former member of these institutions. Since manipulating all these documents would be complicated and costly, I probably would decide to stay with my real but nonaristocratic family history.
This intellectual game illustrates that forging the past is possible but extremely expensive, since it requires rewriting and forging large parts of history in order to embed the fake information into many documents and references of the true history. The costs of doing so are prohibitively high; hence, it is much easier and less expensive to stick with the truth. This step explains how the blockchain utilizes this finding in order to protect its history of transaction data from being forged.
The Goal
It is important that the whole history of transaction data maintained by the blockchain always represents the truth and therefore makes it a trustworthy source for clarifying ownership-related matters.
The Challenge
The blockchain is a purely distributed peer-to-peer system that is open to everyone. Hence, there is a risk that dishonest peers could manipulate or forge the history of transaction data for their own advantage. The challenge is to keep the system open to everyone yet protect the history of transaction data from being forged or manipulated.
137
The Idea
Distinguishing honest from dishonest nodes in an open system in advance is hard or even impossible. Hence, in order to protect the history of transactions from being manipulated by dishonest nodes, we want to prevent anyone from manipulating the history in the first place. If no one can change the history of transaction data, regardless of whether it is honest or dishonest, we do not have to fear that it can be manipulated at all. Hence, making the history of transaction data unchangeable in the first place solves the problem. As a result, the system can stay open to everyone and no one has to worry about dishonest nodes manipulating the history of transactions.
A Short Detour to Immutability
Immutability means that something cannot be changed. Data that are immutable cannot be changed once they have been created or written. For that reason, these data are also called read-only data. Their whole benefit is solely presenting information for reading or presentation purposes. This fact is particularly desirable if one needs to give data to others and hence loses control on how the data are used. Handing over immutable data is an effective way of preventing changes or manipulation of data. Driver’s licenses, passports, and educational certificates are examples of immutable objects in real life.
Authorities produce them in order to document something and their only legible use is to be shown and to be read.
How It Works: The Big Picture
The main idea used by the blockchain to make the transaction history immutable is to make changing it prohibitively costly and make those costs deter everyone from changing it. Making the history of transaction data immutable has three elements:
1. Storing the history of transaction data in a way that even the smallest manipulation of its content stands out and
becomes noticeable.
2. Enforcing that embedding a manipulation in the transac-
tion history requires rewriting a huge part of it.
3. Making adding, writing, or rewriting of data to the history computationally expensive.
Step 16 | Protecting the Data Store
Making Manipulations Stand Out
The blockchain-data-structure that stores data in a change-sensitive manner fulfills the first element. As a result, one cannot silently manipulate data that are part of the blockchain-data-structure and hope that no one will notice it.
Any change will stand out with a huge “noise” caused by breaking hash references that become invalid as a result of changing the data they refer to.
Enforcing Rewriting the History for Embedding
Changes
The blockchain-data-structure also fulfills the second element because it pursues a radical all-or-nothing approach when it comes to changing its data: One either changes the data structure starting from the point that causes the change until the head of the whole chain or one better leave it unchanged in the first place.
Making Adding Data Computationally Expensive
The third element is for those who are not afraid to rewrite large parts of the blockchain-data-structure in the course of having a manipulation embedded in the transaction history. But as soon as writing or rewriting the blockchain-data-structure incurs huge computational costs, people will think twice about whether changing it was a good idea in the first place.
The blockchain-technology-suite makes the content of the blockchain-data-structure immutable by incurring significant computational costs for every block being written, rewritten, or added to the blockchain-data-structure. The computational costs are incurred by hash puzzles that are unique for each block header. 1 As a result, one either accepts the whole cost of changing the data structure from the point that causes the change until the head of the chain by solving a hash puzzle for every block header involved or it is better to leave it unchanged.
1Nakamoto, Satoshi. Bitcoin: A peer-to-peer electronic cash system. 2008. https://bitcoin.
139
How It Works: The Details
The procedure to add a new block to the blockchain-data-structure, as dis-
cussed in Step 15, is not computationally expensive because it only requires adding the hash reference that points to the current head of the chain to the new block header and declaring it as the new head of the chain. The challenge of making the blockchain-data-structure immutable is to make adding a new block a computationally expensive task. The following aspects need to be considered in the course of achieving this:
• Compulsory data of block headers
• The process of creating a new block header
• Validation rules for block headers
Compulsory Data
Every block header of the blockchain-data-structure has to carry at least the following data2:
• The root of a Merkle tree containing transaction data
• A hash reference to the header of the preceding block
• The difficulty level of the hash puzzle
• The time when solving the hash puzzle started
• The nonce that solves the hash puzzle
The Process of Creating A New Block
Creating a new block involves the following steps:
1. Get the root of the Merkle tree that contains the trans-
action data to be added.
2. Create a hash reference to the header of that block that
will be the predecessor from the new block header’s
point of view.
3. Obtain the required difficulty level.
2Okupski, Krzysztof. Bitcoin developer reference. Working paper. 2014.
140
Step 16 | Protecting the Data Store
4. Get the current time.
5. Create a preliminary block header that contains the data
mentioned in points 1 to 4.
6. Solve the hash puzzle for the preliminary block header.
7. Finish the new block by adding the nonce that solves the
hash puzzle to the preliminary header.
Figure 16-1 illustrates the hash puzzle that needs to be solved when adding a new block to the blockchain-data-structure. It shows the data of the block header whose hash value has to fulfill the given restriction or difficulty level, respectively. Note that the difficulty level is part of the block header and hence is also part of the block’s hash value. This ensures that no one can bypass the computational costs of the hash puzzle by arbitrarily reducing the difficulty level.
Figure 16-1. Schematic illustration of the hash puzzle required to be solved when adding a new block to the blockchain-data-structure
Validation Rules
Every block header of has to fulfill the following rules:
1. It must contain a valid hash reference to a previous block.
2. It must contain a valid root of a Merkle tree containing
transaction data.
141
3. It must contain a correct difficulty level.
4. Its time stamp is after the time stamp of its preceding
block header.
5. It must contain a nonce.
6. The hash value of all the five pieces of data combined
together fulfills the difficulty level.
The validation rules ensure that only those blocks are added to the blockchain-data-structure for which the hash puzzle was solved and the computational costs were paid. Rule 4 ensures that the blocks and the transaction data are indeed ordered according to the time being added.
■ Note The activity of adding a new block to the blockchain-data-structure by solving a hash puzzle is also called mining or block mining.
Why It Works
The blockchain-data-structure makes any change of its data stand out due to the fragility of the hash references with respect to changes of the data being referred. This causes the need to rewrite all blocks that are affected by a manipulation. The hash puzzle causes costs for every block that needs to be rewritten in the course of embedding a manipulation. The accumulated costs of rewriting the blockchain-data-structure in the course of embedding a manipulation make it unattractive to manipulate the transaction history in the first place. As a result, the blockchain-data-structure becomes an immutable append-only data store.
The Costs of Manipulating the Blockchain-
Data-Structure
Let’s assume we were going to try to manipulate a particular piece of transaction data that is part of a Merkle tree whose root belongs to a block header located 20 blocks below the current head of the blockchain-data-structure.
Embedding the manipulated transaction data requires the following work: 1. Rewrite the Merkle tree to which the manipulated transaction belongs.
2. Rewrite the block header to which the root of the rewrit-
ten Merkle tree belongs.
Step 16 | Protecting the Data Store
3. Rewrite all succeeding block headers up to the head of
the blockchain-data-structure.
Point 2 requires the solution of a hash puzzle because changing the Merkle root changes the hash value of the block header and hence the solution of its hash puzzle. Point 3 requires solving 20 hash puzzles due to successive changes of the hash references to the previous block header. Under the assumption that solving a hash puzzle takes on average 10 minutes, we would need in total 210 minutes to embed a manipulation in a transaction that belongs to a block header located 20 blocks below the current head. These huge costs deter nodes from changing the blockchain-data-structure.
The Immutable Data Store in the Real World
The immutability of the blockchain-data-structure depends on the computational costs induced by the hash puzzle. The difficulty of the hash puzzles determines how much computational effort and hence how much time is needed to solve them, which in turn determines the immutability of the blockchain-data-structure. If the difficulty is too low, the computational costs of changing the blockchain-data-structure will decline and may no longer be regarded as prohibitively high, which in turn may encourage nodes to manipulate the history of transaction data. On the other hand, if the difficulty is too high, even the computational costs of adding a new block may be regarded as prohibitively high, which in turn discourages nodes from adding new transaction data.
Hence, a challenge in designing a blockchain is to determine the appropriate level of difficulty for the hash puzzles. This challenge is even more demanding as computational power of computers changes due to technical advances. As a result, the difficulty level may need to be determined dynamically.
Blockchain applications in the real world rarely utilize a constant difficulty level for all blocks. Instead they typically utilize a dynamic difficulty level based on the speed at which new blocks are added. 3 This ensures that the time needed to solve the hash puzzle stays at a level that prevents nodes from manipulating the history of transaction data while the actual computational effort may increase.
3Okupski, Krzysztof. Bitcoin developer reference. Working paper. 2014; Wood, Gavin.
Ethereum: A secure decentralized generalized transaction ledger. 2014. http://gavwood.
143
Outlook
This step explained that the blockchain prevents the history of transaction data from being manipulated or forged by turning the blockchain-data-structure into an immutable append-only data store. The next step focuses on making that data store available to everyone in a distributed peer-to-peer system.
Summary
• The blockchain protects the history of transaction data
from manipulation and forgery by storing transaction
data in an immutable data store.
• The history of a transaction is made immutable by utiliz-
ing two ideas:
• Storing the transaction data in the change-sensitive
blockchain-data-structure, which when being changed
requires rewriting the data structure starting at the
point that causes the change until the head of the
whole chain.
• Requiring the solution of a hash puzzle for writing,
rewriting, or adding every single block header in the
blockchain-data-structure.
• The hash puzzle is unique for each block header because
it depends on its unique content.
• The need to rewrite the blockchain-data-structure when it
is changed and the costs of doing so make it unattractive to
manipulate the history of transaction data in the first place.
• Requiring the solution of a hash puzzle for every writing,
rewriting or adding of block headers in the blockchain-data-
structure turns is into an append-only data store.
• A block header contains at least the following data:
• A hash reference to the header of its preceding block
• The root of a Merkle tree that contains transaction data
• The difficulty of its hash puzzle
• The time when solving the hash puzzle was started
• The nonce that solves the hash puzzle
17
Distributing
the Data Store
Among Peers
When computers gossip
Step 16 turned the blockchain-data-structure into an immutable append-only data store, which can be used as a manipulation-resistant ledger for transaction data. Having one immutable append-only history of transaction data in insolation may be of limited value for the goal of clarifying ownership based on a group of computers that acts as witnesses of ownership-related events.
Hence, this step focuses on establishing a purely distributed peer-to-peer system that allows sharing of information about transactions.
The Metaphor
What is the best way to spread some personal news among all employees of a company if you do not have access to a global e-mail distribution list? One approach that guarantees that all employees will eventually receive the news is to share it with one or two well-connected and chatty colleagues and ask
© Daniel Drescher 2017
D. Drescher, Blockchain Basics, DOI 10.1007/978-1-4842-2604-9_17
Step 17 | Distributing the Data Store Among Peers
them to keep the news a secret. This approach works out because there is almost no other information that is more quickly exchanged among colleagues than personal news that is shared under conditions of confidentiality. The reason for this fact is quite simple: Human beings are social creatures who have a genuine interest in their peers, and sharing information about others is a usual behavioral pattern for renewing or strengthening social connections. This step considers an aspect of the blockchain that may portray peer-to-peer systems in a different and almost human light. The aspect that is discussed in this step is the exchange of information among computers by means of communication.
The Goal
The blockchain is a purely distributed peer-to-peer system for managing ownership. It consists of individual computers that maintain their own version of an immutable ledger that stores the whole history of transaction data. Hence, the individual computers are equivalent to witnesses who can testify whether a certain transaction has happened according to their own memories. But how do the individual computers observe or learn about transactions in the first place? Hence, the major goal of this step is to ensure that the individual computers that make up the peer-to-peer system get informed about transactions and are able to maintain their own history of transaction data.
The Challenge
A purely distributed peer-to-peer system does not have any central point of coordination or control. Hence, there is no central component that spreads information to all computers that make up the system. The existence of such a central information point would be a contradiction in terms. In addition, the distribution of information can fail due to technical problems. Hence, the challenge is to have all nodes of the system receiving information of all transactions without falling back to a central component.
The Idea
The idea is to let the computers that make up the peer-to-peer system share and exchange information in the same fashion as humans share news. If the nodes of the peer-to-peer system forward information to their peer nodes, which in turn forward the information to their peers, then eventually all nodes in the system will receive the information.
On a more detailed level, the peer-to-peer system will mimic the way in which groups of humans, such as employees of a company, groups of friends, or the members of a sports club, communicate with one another. In a nutshell, the members of these groups are engaged in three different kinds of conversations that serve district purposes:
147
• Small talk, which serves an important purpose from a
social point of view as it keeps existing relationships alive
but it does not contain any substantial information.
• News, comprising conversations in which substantial
information is exchanged among the participants.
• Introducing new peers, the kinds of conversations that are
necessary to let new people join the existing group of friends or colleagues. Establishing a new relationship and accepting a new member to a group always require some form of initiation rite. This is the point where aspiring members are made
familiar with the group’s history and their values and are
introduced to prominent members of the group.
How It Works: The Overview1
Peer-to-peer systems of computers are the digital equivalent to groups of people. The individual computers that make up the peer-to-peer system also have small talk, exchange news, and accept new members through an initiation rite. These interactions are an integral part of any peer-to-peer system. Similar to human beings who communicate with one another via the medium of spo-ken words, computers in a distributed peer-to-peer system communicate via a digital network. The largest network that connects a huge number of computers is the Internet. Hence, the least expensive way to construct a peer-to-peer system is to let the nodes communicate with one another over the Internet.
Hence, the distributed peer-to-peer system utilizing the Internet as a medium of communication is characterized by the following facts:
• Each computer is connected with the system through the
Internet.
• Each computer is identified by a unique address.
• Each computer can disconnect and reconnect with the
system at any given time.
• Each computer independently maintains a list of peers it
communicates with.
• Communication between nodes is based on messages.
• Messages are sent from one node to another over the
Internet by using their unique Internet addresses.
1Tanenbaum, Andrew S., and Maarten Van Steen. Distributed systems: principles and paradigms (2nd ed.). Upper Saddle River, NJ: Pearson Prentice Hall, 2007; Tanenbaum, Andrew S., and David J. Wetherall. Computer networks (5th ed.). Upper Saddle River, NJ: Prentice Hall, 2010.
Step 17 | Distributing the Data Store Among Peers
The fact that the nodes communicate over a network and that they can disconnect and reconnect at any time influences the delivery of messages. The delivery of messages in such a network has the following characteristics:
• Messages are not guaranteed to arrive at the addressees,
they may get lost instead.
• Messages may arrive more than once.
• Messages may arrive in a different order than they were
sent.
These characteristics cause some hurdles in the communication, but they are solved in the following ways:
• Messages are sent in a gossip style. Every node that
receives new information will forward it to the peers it
communicates with, which in turn will handle the news
in the same way. This ensures that eventually every node
receives the news, even if some individual messages get
lost.
• Due to the fact that messages can be identified by their
digital fingerprint or cryptographic hash value, nodes can
identify duplicates easily and ignore them.
• The fact that transaction data as well as block headers
contain time stamps allows the nodes to order them
based on an objective criterion.
How It Works: The Details
The communication between the nodes that make up the distributed peer-to-peer system has the following three purposes:
• Keeping existing connections alive
• Establishing new connections
• Distributing new information
The first two kinds of communication are mainly focused on the peer-to-peer system itself. They are concerned with keeping the network of peers together and doing some digital housekeeping. But the purpose of the peer-to-peer system is not keeping itself busy just for the sake of staying busy. Instead, the purpose of the peer-to-peer system is the management of ownership.
Hence, the third type of communication focuses on new transaction data and new blocks to be added to the blockchain-data-structure. This information is needed by every node of the system in order to maintain its own version of the transaction history.
149
Keeping Existing Connections Alive
Each computer in the network independently maintains a list of peers it communicates with. This list contains only a subset of all nodes that make up the whole system. This is similar to employees who maintain social connections to some of their colleagues, comprising only a subgroup of all the employees of the same company. On a regular basis, each computer verifies that these peers are still available. This is done by sending peers a small message, often called ping, with the request to answer it with a message called pong. Peers that repeatedly do not answer these messages are removed from the list of peers. This is similar to small talk between colleagues, which mainly serves the purpose of keeping the social relationship alive.
Establishing New Connections
Every computer can request to join the peer-to-peer system by sending a corresponding request message to any of the nodes that make up the system. The requested node adds the address of the inquirer to its list of peers and sends a confirmation as reply. When receiving the reply the node will add the address of the sender to its own list of peers as well. As a result, a new connection is established and the system has grown by one more node. Having only one connection to the system is risky as every node can terminate a connection, shut down, or even crash at any time. Hence, when joining a peer-to-peer system, a computer typically establishes connections to many different nodes that are already part of the system. This ensures that the connection to the system as a whole is maintained, even if individual nodes disconnect or shut down.
Distributing New Information
This kind of communication serves the application goal of the system that is managing ownership. This is done by forwarding new transaction data and new blocks to be added to the blockchain-data-structure in a gossip type of information forwarding. Sharing ownership-related information happens in the following three occasions:
• In an ongoing fashion: new information (e.g., new transac-
tion data and new blocks) are distributed as they occur.
Every node connected to the system will eventually
receive all news.
• As an update: nodes that reconnect to the system after
they were disconnected for a while will receive all trans-
action data and blocks they have missed out in the
meantime.
Step 17 | Distributing the Data Store Among Peers
• As part of the on-boarding procedure: new nodes that
join the system have not had the chance to build their
own history of transactions because they have never been
connected with the system before. Hence, they need to
get the whole history of transactions that happened up
to the time they joined the system. Transferring a copy
of the whole up-to-date version of the blockchain-data-
structure to the newbie node ensures that it becomes
a full-fledged node after joining the system. This type of
information delivery can be seen as an extreme case of
an update: an update of the whole history of transactions